Intro
After a few months focused on LLM iteration work and a personal LLM project, I wanted to write down a practical workflow for model iteration. This series is about the engineering process around model changes: how a team evaluates them, integrates them, tests them, deploys them, and watches them after release.
In production systems, model iteration means updating the model, model provider, prompt, inference configuration, or serving path behind a product feature. In personal projects, it can be as simple as adding another model engine to the application. In both cases, the core challenge is the same: new models arrive quickly, but adopting them safely requires a repeatable process.
This series focuses on LLM products. The details may differ for other ML systems, but the high-level workflow is still useful: validate the research, validate the infrastructure, test the full product path, then deploy with monitoring and rollback plans.
Model Iteration Workflow
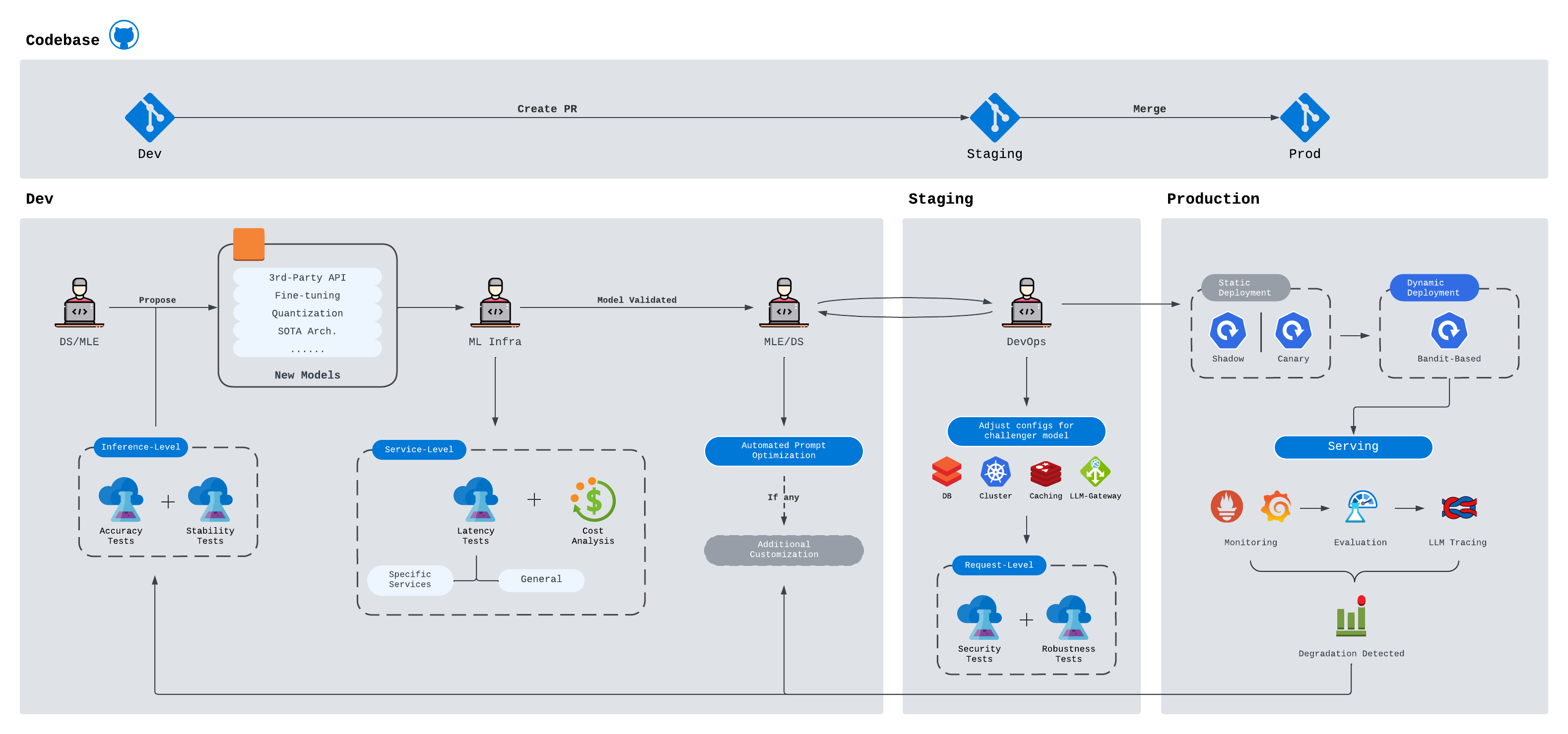
Like a software CI/CD pipeline, a model iteration workflow can be split into three broad phases: development, staging, and production.
In development, data scientists, machine learning engineers, and infra engineers validate whether a proposed model change is worth moving forward. The goal is to satisfy the CLASS objective:
- Cost: Can the system afford the change?
- Latency: Can the user experience tolerate the change?
- Accuracy: Does the change improve the task that matters?
- Security: Does the change preserve product and data safety?
- Stability: Does the change behave consistently enough for production?
In staging, the team prepares the full service path and runs deeper integration, end-to-end, security, and user-acceptance tests. This is where the model stops being a research artifact and starts behaving like part of the product.
In production, the team deploys gradually, monitors behavior, catches regressions, and prepares future training or evaluation data from observed failures.
The rest of this post walks through each phase at a high level. The later posts in the series go deeper into research validation and infra validation.
Development
Development is where most model iteration ideas should either become stronger or die cheaply. The team should be able to answer whether the proposed change has enough evidence to justify infra, QA, and product testing.
Model Investigation
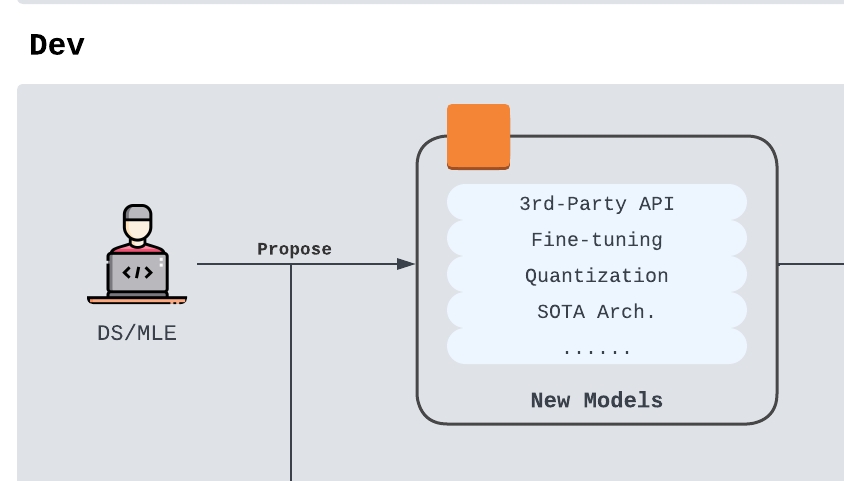
The process usually begins with model investigation. Data scientists and machine learning engineers track new model releases, provider changes, architecture improvements, fine-tuning opportunities, quantization methods, and inference optimization options.
Common investigation paths include:
- Third-party API providers: Hosted providers are often the fastest path to a strong baseline. They can reduce setup time, but may introduce vendor dependency, privacy concerns, or long-term cost risk.
- Fine-tuned models: Fine-tuning can improve performance for a specific product task, but it requires high-quality data, careful evaluation, and more maintenance.
- Quantization and inference optimization: For in-house serving, the right quantization method, runtime, batching strategy, and inference engine can make a large difference in latency and cost.
The output of this stage should be a clear model-change proposal, not just an interesting experiment.
Model Configuration Optimization
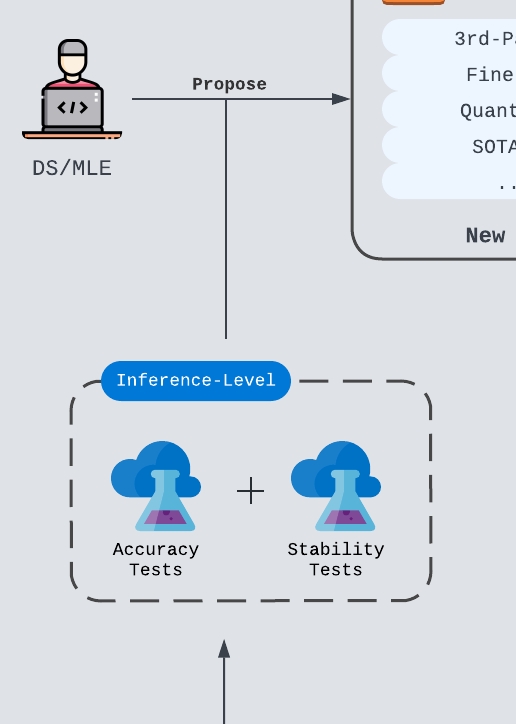
Once the team has a candidate model setup, it should optimize the full inference configuration: model version, provider, prompt, temperature, maximum tokens, structured-output mode, streaming behavior, and any preprocessing or post-processing logic.
Two tests matter most at this stage:
- Accuracy tests: Compare the candidate against ground truth or the current production baseline. A candidate should pass only if the improvement is meaningful for the product, not merely visible in a small sample.
- Stability tests: Check whether similar inputs produce consistent outputs. This is especially important for classification, data analysis, chatbot workflows, and any product path where users expect predictable behavior.
Prompt engineering often happens during this stage, but it should be disciplined. A prompt improvement that only works for a small handpicked set of examples can hide larger stability or latency issues.
Model Serving Tests
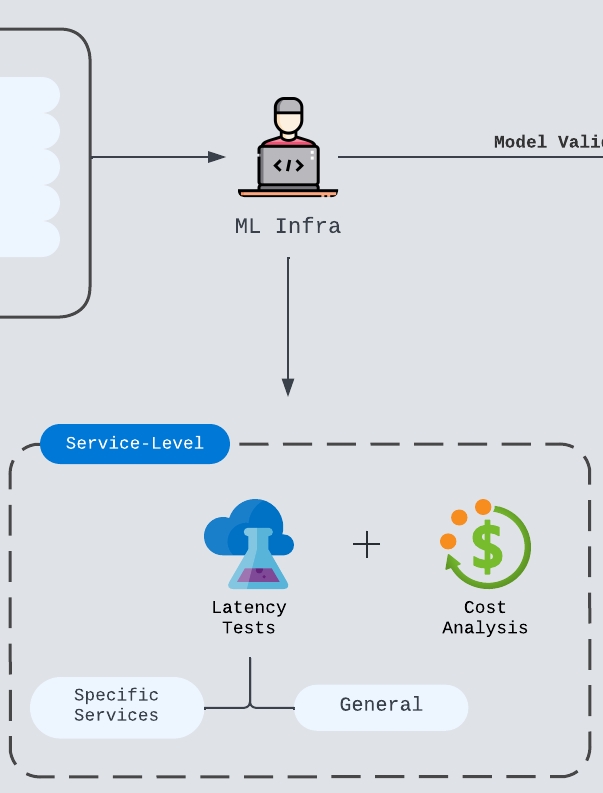
After the model configuration is stable enough, infra validation begins. ML infra engineers should test serving compatibility, load behavior, input/output-size sensitivity, failure modes, and cost impact.
This is where latency and economic tradeoffs become concrete. The team should understand whether the model update reduces cost, increases cost, requires a new vendor, changes token usage, or demands a different serving stack.
Prompt Optimization
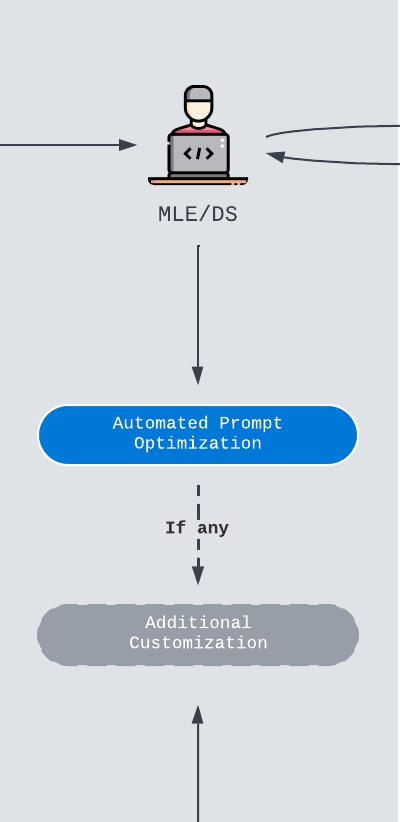
Before staging, the team can further optimize prompts for the tasks that the candidate model will handle. This may involve manual prompt review, UI-based prompt iteration, automated prompt search, or better in-context examples.
The important principle is to optimize prompts after the team understands the model’s baseline behavior. Otherwise, prompt changes and model changes become tangled, and it becomes difficult to know what actually improved the system.
Staging
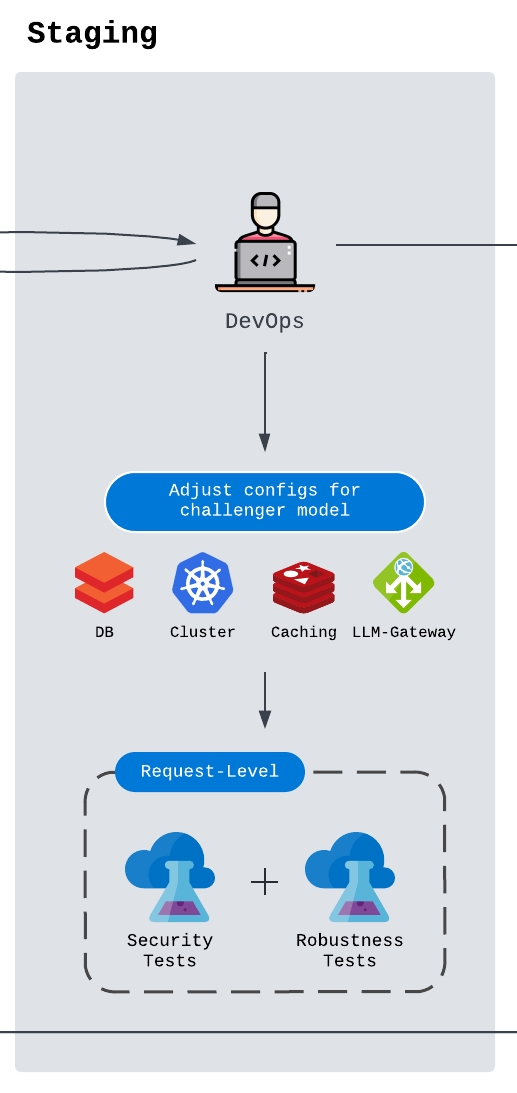
Staging is where the model setup is integrated into the full product environment. DevOps or ML infra engineers need to update the relevant database entries, clusters, model gateway, service configuration, cache behavior, streaming middleware, and routing logic.
The staging phase should include:
- Integration tests across the services that call the model
- End-to-end tests on realistic user workflows
- Guardrail and security checks at the request and response level
- Red-team or abuse-case testing when the product risk justifies it
- Drift checks for model behavior, prompt behavior, and data distribution
- Rollback and fallback validation
This is also where product managers, customer-support engineers, or domain experts may notice loopholes that did not appear in research validation. Their feedback can become valuable evaluation data for later iterations.
Production
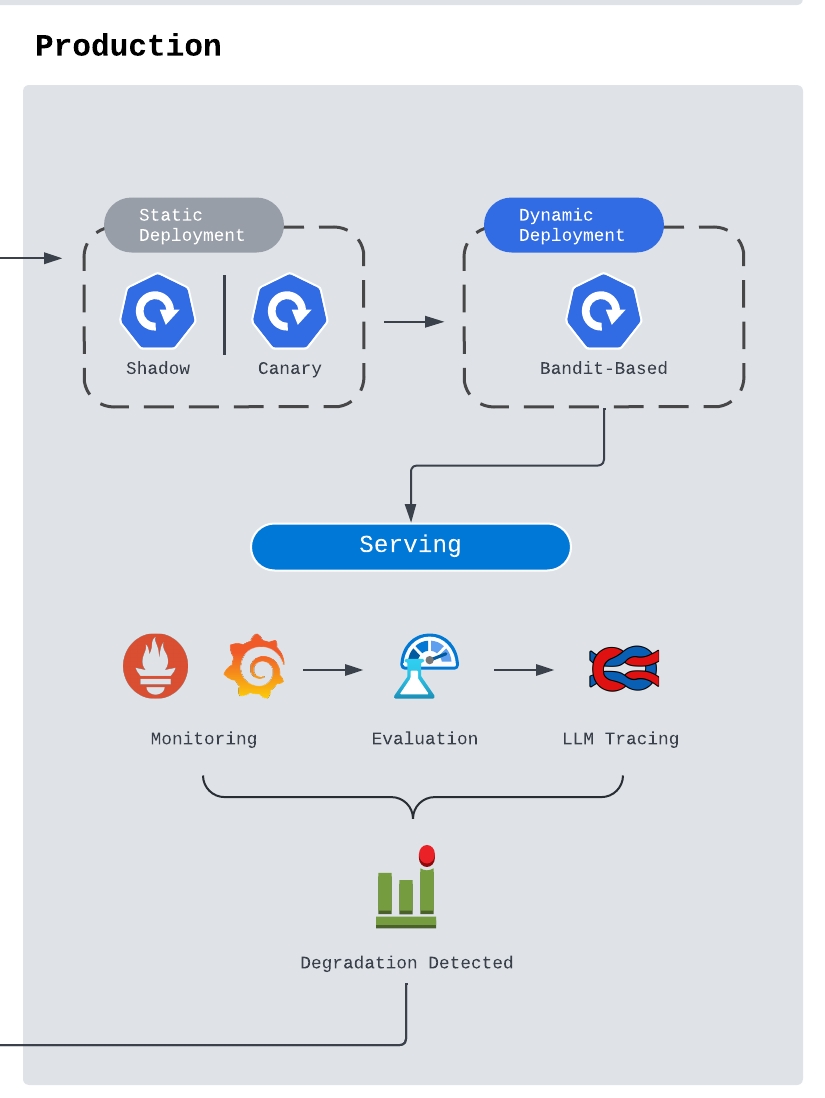
After staging approval, the model change can move to production. Deployment should usually be gradual. Static rollout strategies such as canary deployment are a good starting point because they let the team route a small portion of traffic to the new model, observe behavior, then expand or roll back.
Production also needs a complete monitoring stack:
- Latency and error-rate dashboards
- Cost and token-usage tracking
- Model-output quality checks
- Tracing across model calls and service dependencies
- Alerts for degradation or abnormal behavior
- Fallback paths when the candidate model fails
When degradations happen, the team should preserve the failing inputs, outputs, traces, and labels. These failures become valuable data for future evaluation, fine-tuning, QA testing, and prompt improvement.
To Be Continued
This wraps up the high-level map of model iteration. The process can look heavy at first, but the structure is what keeps model updates from becoming chaotic. Each stage answers a different question:
- Research validation asks whether the idea is worth pursuing.
- Infra validation asks whether the system can support it.
- Staging asks whether the product path still works.
- Production asks whether the change remains healthy under real traffic.
The next posts go deeper into the first two stages: validating model research and validating model infra.