Topic Modeling with Latent Dirichlet Allocation
Overview
Topic modeling: Topic modelling refers to the task of identifying topics that best describes a set of documents. In this blog, we discuss about an popular advanced model that
Definition
To explain in plain word:
LDA imagines a fixed set of topics. Each topic represents a set of words. The goal of LDA is to map all the documents to the topics in a way, such that the words in each document are mostly captured by those imaginary topics.
An important note to take is that LDA aims to explain the
document-levelidea, meaning it has less focus on the meaning of each word/phrase in the document, but rather the topic the document falls underDirichlet Process:- A family of stochastic process to produce a probability distribution
- Used in Bayesian Inference to describe the
priorknowledge about the distribution of random variables
Dirichlet Distribution:- Basically a multivariate generalisation of the Beta distribution:
where is a beta distribution - Outputs:
where - Often called “a distribution of distribution”
symmetric Dirichlet distribution: a special case in the Dirichlet distribution where allare equal, hence use a single scalar in the model representation - Impact of
: (a scaling vector for each dimension in ) : - Sparsity increases
- The distribution is likely bowl-shaped (most probable vectors are sparse vectors like
or - In LDA, it means a document is likely to be represented by just a few of the topics
- Sparcity decreases
- We will have a unimodel distribution (most probable vectors are in the center)
- In LDA, it means a document is likely to contain most of the topics
makes documents more similar to each other
- The conjugate prior of multinomial distribution is a Dirichlet distribution
- Basically a multivariate generalisation of the Beta distribution:
LDA\s keywords
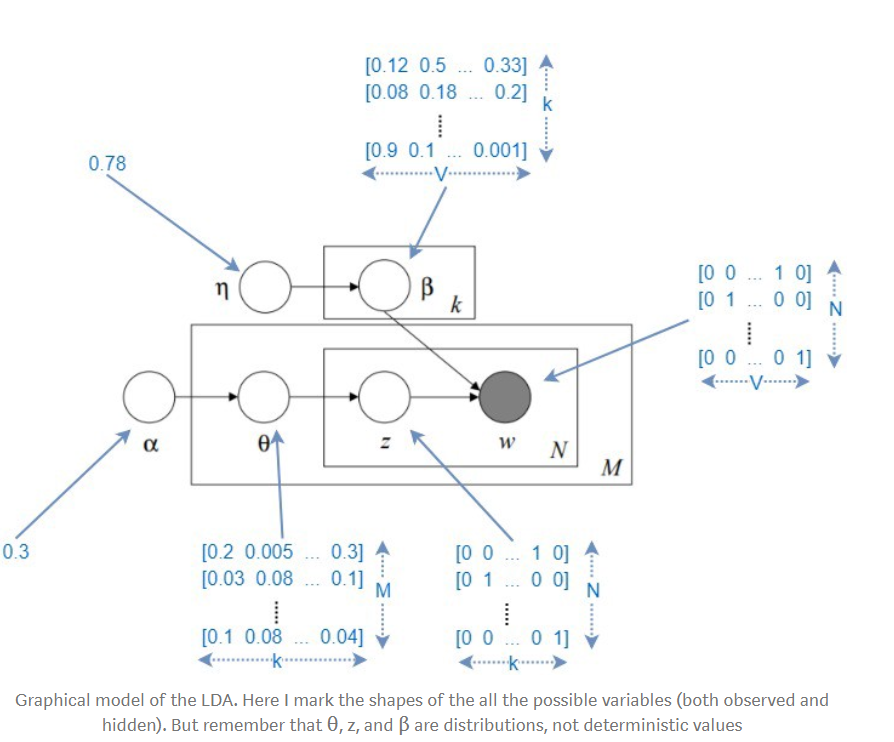
k: Number of topics a document belongs to (a fixed number)V: Size of the vocabularyM: Number of documentsN: Number of words in each documentw: A word in a document. This is represented as a one hot encoded vector of size VW: represents a document (i.e. vector of "w"s) of N wordsD: Corpus, a collection of M documentsz: A topic from a set of k topics. A topic is a distribution words. For example it might be, Animal = (0.3 Cats, 0.4 Dogs, 0 AI, 0.2 Loyal, 0.1 Evil)θ: The topic distribution for each of the document based on a parameterαβ: The Dirichlet distribution based on parameterη
LDA's procedure
This is quite complicated
LDA's document generation
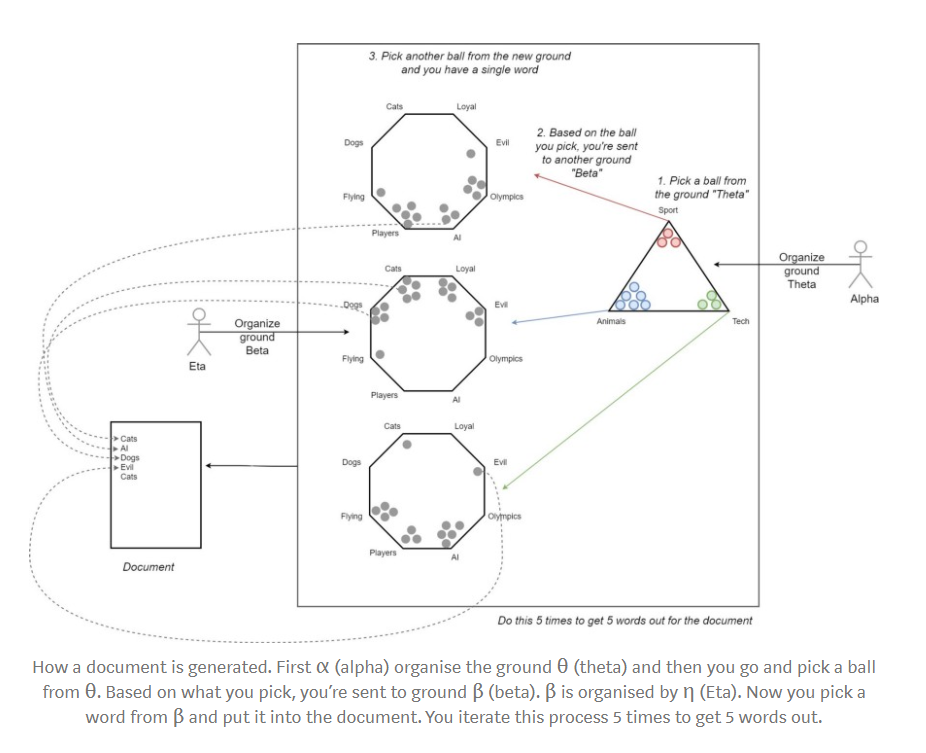
αhas a topic distribution for each document (θ ground for each document) a (M x K) shape matrixηhas a parameter vector for each topic. η will be of shape (k x V)- In the above drawing, the constants actually represent matrices, and are formed by replicating the single value in the matrix to every single cell.
θis a random matrix based on dirichlet distribution, whererepresents the probability of the th document to containing words belonging to the th topic a relatively low βis also a dirichlet distribution asθ,represents the probability of the th topic containing the th word in a vocabulary of size ; The higher the , the more th topic is likely to contain more of the words, and makes the topics more similar to each other - Detailed steps:
- For each topic, draw a distribution over words
- For each document
- Draw a vector of topic proportions
. E.g: [climate = 0.7, trade = 0.2, housing = 0.1, economy = 0] - For each word slot allocated, draw a topic assignment
, then draw a word
- Draw a vector of topic proportions
- We want to infer the join probability given our observations,
- We infer the hidden variables or latent factors
by observing the corpse of documents, i.e. finding
- We infer the hidden variables or latent factors
- For each topic, draw a distribution over words
The learning part
Idea 1:
Gibbs sampling:A point-wise method (Possible but not optimal)
Intuition: The setting which generates the original document with the highest proability is the optimal machine
The mathematics of collapsed gibbs sampling (cut back version)
Recall that when we iterate through each word in each document, we unassign its current topic assignment and reassign the word to a new topic. The topic we reassign the word to is based on the probabilities below.where
- number of word assignments to topic in document - number of assignments to topic in document - smoothing parameter (hyper parameter - make sure probability is never 0) - number of words in document - don’t count the current word you’re on - total number of topics - number of assignments, corpus wide, of word to topic - number of assignments, corpus wide, of word to topic - smoothing parameter (hyper parameter - make sure probability is never 0) - sum over all words in vocabulary currently assigned to topic size of vocabulary i.e. number of distinct words corpus wide Done with each word in a document (to classify them into a topic)
Done in an iterative way (different topics for same words in a document: 1st "happy" may be topic 1, which affects 2nd "happy" to be topic 2 in the same document)
Main steps:- For each word
in a document : - The word will be allocated to
- Note that
is the one used in the original and in - Iterate until each document & word's topic is upadted
- Aggregate the results from all documents to update the word distribution
for each topic - Repeat the previous steps until corpus objective
converges
- For each word
Idea 2:
variational inference:- The key concept of variance inference is approximate posterior
with a distribution using some known families of distribution that is easy to model and to analyze. - Then, we train the model parameters to minimize the
KL-divergencebetween q and p. KL-divergence:,also called "relative entropy" - Further reduction in complexity for high dimensional distribution is possible
- The key concept of variance inference is approximate posterior
Idea 3:
Mean-field variational inferencebreaks up the joint distribution into distributions of individual variables that are tractable and easy to analyze

It is not easy to optimize KL-divergence directly. So let us introduce the
Evidence lower bound (ELBO)- by maximizing ELBO, we are minimizing KL-divergence: view explanation here
- When minimizing ELBO, we don’t need Z. No normalization is needed. In contrast, KL’s calculation needs the calculated entity to be a probability distribution. Therefore, we need to compute the normalization factor Z if it is not equal to one. Calculating Z is hard. This is why we calculate ELBO instead of KL-divergence.
There are a lot of math details involving exponential family operations, but the general picutre is captured by the graph below

Evaluation using similarity query
Ok, now that we have a topic distribution for a new unseen document, let's say we wanted to find the most similar documents in the corpus. We can do this by comparing the topic distribution of the new document to all the topic distributions of the documents in the corpus. We use the Jensen-Shannon distance metric to find the most similar documents.
What the Jensen-Shannon distance tells us, is which documents are statisically "closer" (and therefore more similar), by comparing the divergence of their distributions. Jensen-Shannon is symmetric, unlike Kullback-Leibler on which the formula is based. This is good, because we want the similarity between documents A and B to be the same as the similarity between B and A.
The formula is described below.
For discrete distirbutions
and , the Jensen-Shannon divergence, is defined as where
and
is the Kullback-Leibler divergence The square root of the Jensen-Shannon divergence is the Jensen-Shannon Distance:
The smaller the Jensen-Shannon Distance, the more similar two distributions are (and in our case, the more similar any 2 documents are)
Pros & Cons
Pros
- An effective tool for topic modeling
- Easy to understand/interpretable
- variational inference is tractable
- θ are document-specific, so the variational parameters of θ could be regarded as the representation of a document , hence the feature set is reduced.
- z are sampled repeatedly within a document — one document can be associated with multiple topics.
Cons
- Must know the number of topics K in advance
- Hard to know when LDA is working - topics are soft-clusters so there is no objective metric to say "this is the best choice" of hyperparameters
- LDA does not work well with very short documents, like twitter feeds
- Dirichlet topic distribution cannot capture correlations among topics
- Stopwords and rare words should be excluded, so that the model doesnt overcompensate for very frequent words and very rare words, both of which do not contribute to general topics.
Real-word application
Text classification
Book recommender
Article clustering/image clustering
understanding the different varieties topics in a corpus (obviously)
getting a better insight into the type of documents in a corpus (whether they are about news, wikipedia articles, business documents)
quantifying the most used / most important words in a corpus
document similarity and recommendation.
Long Code example
1 | # import dependencies |
Topic Modeling with Latent Dirichlet Allocation
https://criss-wang.github.io/post/blogs/supervised/topic-modeling/