Model Iteration Series: Validating Model Research
Intro
As the first part of the model iteration, or any form of production-driven research projects that commonly take place in industry, we need to conduct data science or machine learning researches on the various components in a product pipeline. For this write-up, we are going to focus on the various steps and preparations needed for a proper LLM model-based research.
If you haven't read my blog that provides the high level insights to the series, I would urge you to kindly go through it to gain more context on this write-up. It is important to consider it as an integral part of the entire series, as I will mainly focus on a few parts of the model research. Specifically, I must emphasize that this blog is for LLM models. The considerations and design decisions required for other ML/AI models may be drastically different.
In the upcoming sections, I will discuss the following topics:
- Different forms of model investigations and how they become crucial to the iteration process
- A proposed strategy to run LLM model investigation for Startup-like DS/ML/AI teams
- How to run inference tests effectively
- Some important points to take note of during LLM model research
Model Investigation
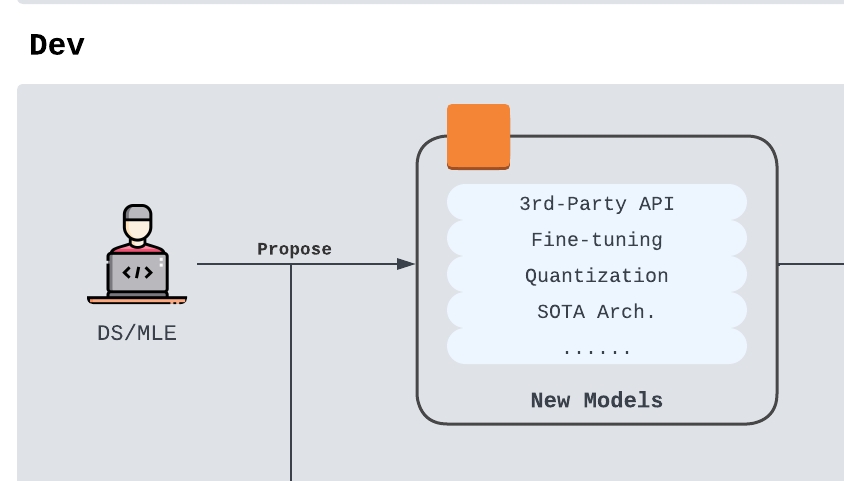
To reiterate from the intro blog, in a common model investigation process, we have 3 major types of model improvements that can be proposed:
- A better third party API
- A better model architecture
- A better set of model parameters ( customization, finetuning, etc…)
Each type has its strength and weaknesses, as shown in the table below. They are interconnected to some extend, and some may be tested in parallel or in combination. However, all of them should eventually provide business value to the company directly or indirectly.
| Time Span | Short-term Cost | Long-term Cost | Manpower | Performance Improvement | Suitable for | |
|---|---|---|---|---|---|---|
| Third Party API | Short | Low | High | Low | Low/Medium | Startups |
| Model Architecture-based | Long | High | Low/Medium | High | Depends | Big Tech |
| Model Parameter-based | Medium | Medium | Low | Medium | High | Startups & Big Tech |
All ML/DS researchers that investigate these methods should be extremely cautious when proposing model changes to the existing ML system, as their investigations are the first line of defense when it comes to new ideas. Having experienced the tremendous effort of repeated validation process gone to drain simply because of flaws in research assumption has taught me the valuable lesson of double checking, even triple checking conjectures, changes, and impacts before presenting ideas for further testing. Therefore, I’ve been developing robust validation systems like the llm-validator myself inside and outside of work. I sincerely wish every team that’s responsible for LLM model investigation would be able to come up with some system like (and of course, better) this one to automate preliminary model validation during the research process.
Proposed Strategy for Model Investigation
Every team that works on LLM has its own way of working towards better LLM models at different stages in the company development. In this section, I would like to propose a potentially valid and efficient method for teams that are in early stages (e.g. Startups, or newly formed LLM teams due to the AI frenzy). It's a 5-step process:
Step 1: Pick a baseline model
Most new teams don't have ready insights on a specific model to use for specific tasks they are given at the start. Thus any widely adopted universal model can be its starting point. The model can be some third party API providers like Bedrock, Anyscale or Together, or any direct model providers like OpenAI, Google or Anthropic. Avoid going into the trap of premature optimization in early stages. When things have not scaled up yet, the cost of using these large models far outweigh the cost of additional troubles caused by small open-source models or custom inference engines in the near future.
Ultimately, this model will become a baseline for new model changes proposed, and will remain as a reference point when models iterate. As our validation data changes, the statistics related to the baseline model should automatically change as a result.
Step 2: Pick a configuration
The model configurations here I want to suggest encompass the entire inference process. It includes the right set of parameters during API calling, like temperature, max_tokens, top_p, is_streaming or function_calling. It also includes the choice of providers. These design decisions are highly dependent on the tasks LLMs are trying to solve, and the side-effects that can be caused by them.
Step 3: Consider the Projected Impact
This step is often ignored by many junior scientists (including myself) who work on model iteration investigation. In order to make the change useful to the product/business, here are 5 important spectrums to consider:
- Cost: amount of cost saving this change can bring
- Latency: reducing inference time or end-to-end process duration can boost customer satisfaction and secure more business eventually
- Accuracy: the performance boost is often the most obvious from science’s perspective, but often the less obvious in the product. Nonetheless, a significant leap in performance is usually the ultimate factor that enables a product to win.
- Security: Guardrail against attacks or harmful contents have been well studied in the last couple of years. It is the bottom-line of the product.
- Stability: it is the most ignored aspect among scientists, especially in LLM. Many researchers choose to “intentionally” ignore stability as they attribute it to the inherent variations LLMs. However, bugs/issues will be reflected out of it, and they are easily sensed by the product users. Moreover, it is the hardest to identify.
Think through each spectrum carefully ensures that we do not hurt other spectrums significantly when we focus on improving one or two aspects. This prevents a ton of issues from happening when we move into the later stages of model iteration.
Step 4: Observe, Execute, and Analyze
I have always had trust in my fellow colleagues for their resourcefulness while searching for model changes. They know how to find the right set of tools to run experiments, make tweaks, and analyze results to further ensure the required model changes are formed and validated. This step is by far the hardest (because it involves lots of execution and thinking), and yet the most trusted part.
In order to offer some additional guidance to people who are still new to model validation, I have included in the bottom section a demo using my llm-validator repo on how to run a validation process when we change from GPT-4 to Claude 3.5 Sonnet. The same steps can be reproduced across many model changes, and can be done in a systematic way.
Step 5: Compile and Ship
Provide the proposed model changes and the updated model metadata to ML Infra engineers will be the final step of this model investigation process. Ensure proper documentation, fallback plans and justification are ready in place. It will then go for a more intricate latency test and cost analysis thereafter.
More on Accuracy and Stability
At the model investigation stage, even though we have to consider all 5 spectrums of the CLASS objective, we won't necessarily have the resources, scope and expertise to fully evaluate cost, latency and security. Hence researchers are most likely gonna focus on accuracy and stability. Here, I will share my two cents on an ideal workflow to conduct these tests after we formulate and implement the changes in code.
A/B Testing is the basic
It is almost a second nature for DS/MLE to conduct A/B testing when they are given a proposed solution and a baseline solution. The same should be said for accuracy and stability tests. The usual way of A/B testing still holds. If you're still unfamiliar with it, I urge you to follow some tutorials to understand the steps to run it. You can ready any materials online, or just take a shortcut and read my post here.
Components of the inference
We use A/B testing as the backbone of these tests, and now it is time to fill up the content:
- Task: what is the input/output format? what is the expected outcome & format? why is it critical to test model changes on this task?
- Dataset: where is the raw input sourced from? how is it labeled (human vs LLM)? what’s the size? is there potential data quality issues?
- Model/Engine: what are the basic config parameters? is it supposed to be time-consuming? what is the cost of model inference for each complete test? are there error handling mechanisms that ensure the tests run smoothly?
- Prompt: what is the prompt being used? are we using the same one the baseline model is using? what version and what variables? do we have a metaprompt for it?
- Metrics: what are the set of scores we need to measure? is it naturally varying a lot? is there any obsolete metric we need to replace with new ones?
When it comes to accuracy, we must ensure the testing data is large enough to cover the input domain well, and the metric is reflective of the goal. For example, if we are to run chunk validation using LLM, then we should consider aspects like chunk relevancy, chunk precision/recall, and ensure the knowledge base is well represented by the chunks in datasets. The results against baseline should also be statistically significant for the proposed solution to hold.
When it comes to stability, there should be datasets with very similar queries. We have the expectation of identical, or if not, very similar outputs from the model using these similar queries, similarity scores should be measured, and deviations should be further analyzed and further model tuning may be requested upon issues identified.
Logging
Run the tests and generate statistics for it. A good validator should be able to return the results in forms of distributions, output datasets and metric scores. In the meantime, it should log any warnings and errors that may alert the researchers the hidden danger of applying this change to production systems.
A simple demo of validation GPT -> Claude migration
For the rest of the blog mostly contains a demo to show how the validation part is achieved via a systematic pipeline. In this demo, we set up a story that some DS found out Claude-3.5-sonnet performs much better than GPT-4 and decides to propose that migration for a code generation service. Our role is to validate such proposal from the accuracy perspective using an llm-validator.
Step 1
As a first step, clone the repo [Link], and specify the major components:
Task: Code generation
- Input: user query with code snippet
- Output: completed code section
- Expectation: Code is complete and correct
Dataset: a simple demo dataset can be found in the repo: Link
- Note: to achieve A/B testing, you should curate sufficient data with multiple batches to make it statistically significant.
Model: We have two models to investigate, so we use AnthropicClient and OpenAiClient
Note: if you need to use a custom client, please refer to the implementations here as a guideline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52import os
from typing import List, Dict
import anthropic
from llm_validation.components.clients import Client
from llm_validation.app.configs import ClientConfig
class AnthropicClient(Client):
def __init__(self, config: ClientConfig):
super().__init__(config)
self.api_key = os.getenv("ANTHROPIC_API_KEY")
async def predict_stream(self, messages: List):
client = anthropic.Anthropic(api_key=self.api_key)
stream = client.messages.create(
model=self.model_name,
system=messages[0]["content"],
messages=messages[1:],
stream=True,
**self.model_options,
)
for chunk in stream:
if chunk.type == "message_start":
self.input_tokens = chunk.message.usage.input_tokens
elif chunk.type == "content_block_delta":
yield dict(
text=chunk.delta.text,
raw_response=chunk,
)
else:
continue
async def predict(self, messages: List) -> Dict:
client = anthropic.Anthropic(api_key=self.api_key)
response = client.messages.create(
model=self.model_name,
system=messages[0]["content"],
messages=messages[1:],
**self.model_options,
)
return dict(
text=response.content[0].text,
raw_response=response,
usage=dict(response.usage),
)
def extract_usage(self, type: str = "input") -> int:
if type == "input" and self.input_tokens:
return self.input_tokens
Prompt: stored in yaml format
- task prompt:
code_generation.yaml - judge prompt:
judge.yaml
Metrics: We need to use llm-as-a-judge for this performance evaluation. It is readily defined in the repo as. CodeGenAccuracy under components.metrics.accuracy file, feel free to edit it to fit your needs.
1 | class CodeGenAccuracy(AccuracyMetric): |
- Note: similar to customizable
client, my code enables great flexibility for you to define additional metrics, just refer to themetricfolder to find things you need.
Step 2: Define the configuration
The configuration file should be stored under configs/{your_taks_name} folder. In this demo, it is configs/code_generation/openai.json and configs/code_generation/anthropic.json. The config follows the format as shown below:
1 | { |
In this demo, I’ve already provided the completed configuration for you. If you would like to customize the config, refer to the configs.py to understand the additional set of parameters.
Step 3: Run experiment
Run pip install -e . and pip install -r requirements.dev.txt to set the project up. Notice that you may need to have a Weights & Biases account for experiment logging. After that, we are ready to kick-off the experiment by running the following command:
1 | llm-validator run --config-path=configs/code_generation/openai.json |
You will be able to see the results both from console and from W&B dashboard. A sample outcome would look like the following
1 | Calling LLM: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.56s/it] |
Step 4: Repeat for both models
Remember to run multiple epochs on different datasets, aggregate and analyze.
And hooray!!! We have completed a first attempt at validating the migration proposal.
A take-home challenge
Notice that I described the metric implementation for accuracy, but not stability. Investigating stability is a completely different challenge, and I urge you to try implementing the metric logic yourself. If you have any question, raise a issue in the repo, and I'll clarify it for you with respect to this interesting challenge.
Final words
Once again, the endeavor to further improve the model iteration process does not stop here. We have a lot more to go through from the model serving perspective, and it will become much more tricky from there onwards. Nonetheless, that's where a whole new world unfolds in front of us, especially those new grads who mostly deal with static and performance-oriented services building. Before that blog comes out, Stay Hunger, Stay Foolish.
Model Iteration Series: Validating Model Research
https://criss-wang.github.io/post/software/model-iteration-research-validation/