Model Iteration Series: Intro
Intro
After pausing the blog updates for a few months in order to fully focus on my LLM iteration work and my personal LLM project, I think it is about time to stop by and share my thoughts on an important topic for LLM - Model iteration.
Model iteration refers to the update of models used in produciton-level services. When it comes to personal projects, model iteration can also be the attempt to include additional models into the pool of engines that supports the application logic. As we enter the era of AI boom, we are bound to be inundated by lots of new models, many claiming to be the SOTA and beating each other from time to time. Hence, rapid prototyping with the latest models become extremely important.
Here I'll give a practical guide on model iteration process in tremendous depth based on my current experience with LLMs. It'll come in a series of blogs in Software Engineering sections, as it is more of an engineering architectural design rather than algorithmic details. This blog will just be an introductory guide, laying out the full pipeline step by step. For details on each step, stay tuned for future updates.
Model Iteration Workflow
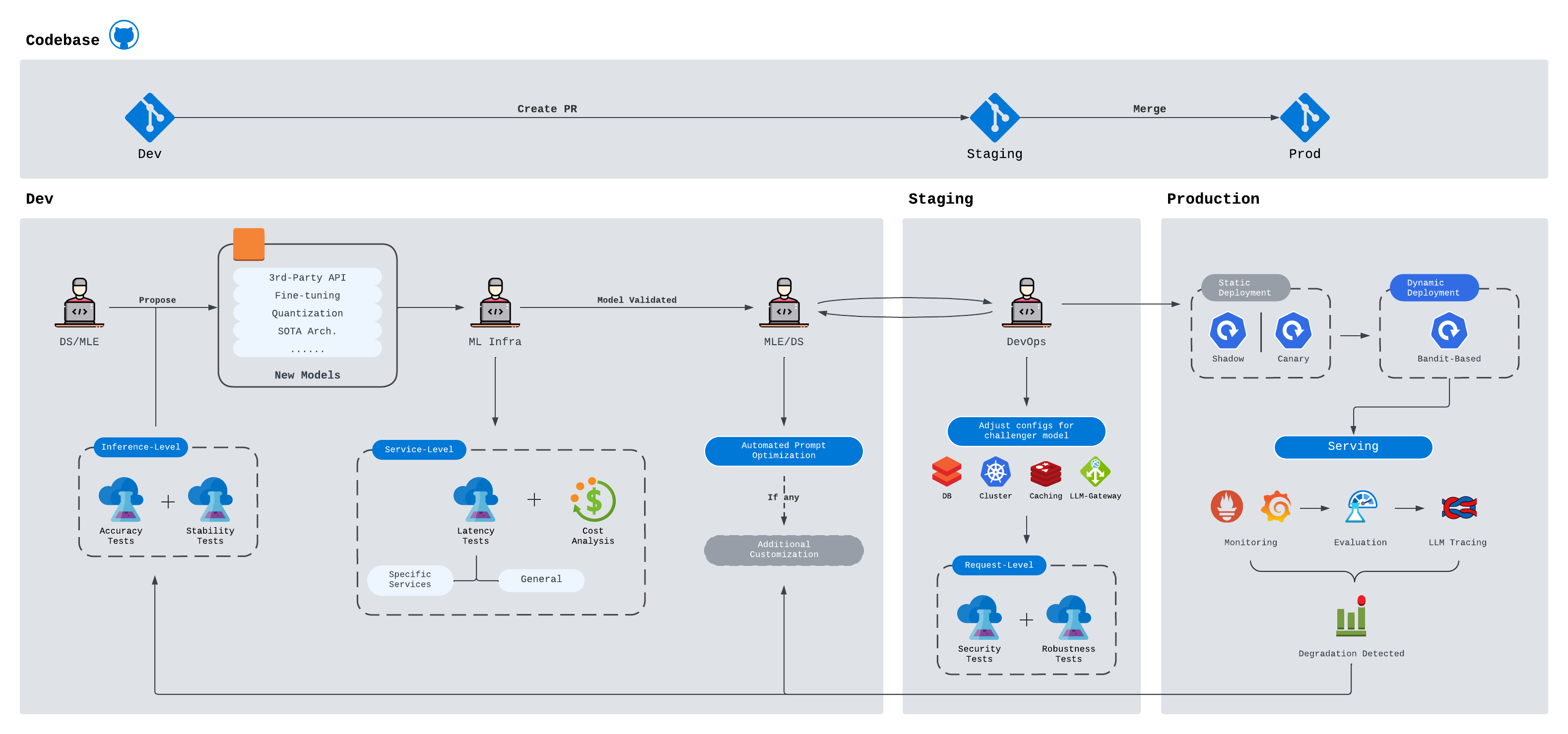
Like any SWE project’s CICD, the entire iteration flow can be split into Dev/Staging/Prod sections. In Development section, engineers and scientists will collaborate to validate new models proposed, with a goal of satisfying the CLASS objective: Cost, Latency, Accuracy, Security and Stability. This entire process will include identifying the best model configurations, inference engines and optimizing the prompts for different tasks. Once these setups are finalized, we enter into the Staging section, where DevOp engineers or ML Infra engineers will be responsible for integration testing and E2E testing on various services, queries and tasks. More rigorous tests and more critical tests are required in this stage. Detailed reviews from leadership are also required to endorse the adoption of the model. Finally as we enter prod section for deployment, many operational tasks recently captured the attection of the LLM industry, and will be highlighted as we go through them in depth.
For reference purpose, I've drafted a simple workflow. You may use it at your discretion, and change any part as you deem necessary. In the upcoming sections, I will follow this chart and explain each component and their purposes.
Development
Model Investigation
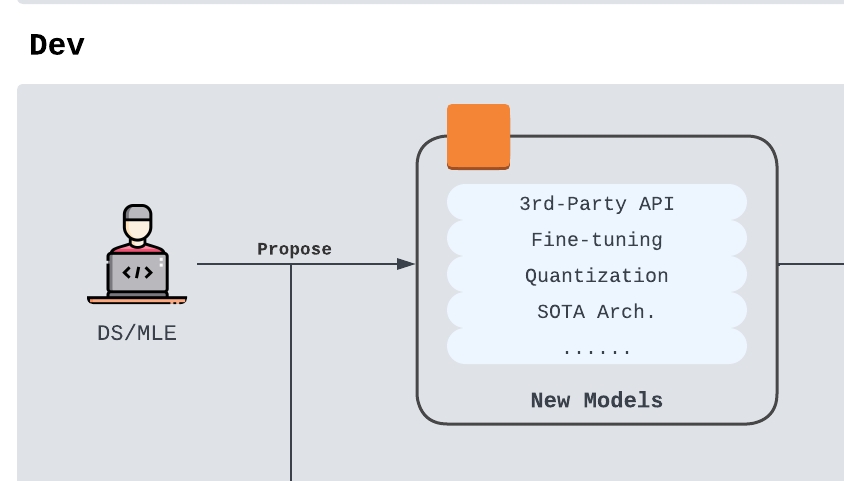
To kickstart the process, data scientists and machine learning engineers in the team will keep themselves updated with the latest model progress in the field, and run model investigations periodically. This can come in the form of:
- Third Party API providers
This is often the most convenient and least secure option. Companies like Together AI, Anyscale AI, AWS Bedrock, Vertex AI often collaborate with model providers to offer the cheapest and most efficient inference options that beats many in-house models. Nonetheless, they often fall short when it comes to finetuned models. - Finetuning Models
Finetuning models on production-level datasets are often the best options to improve model performance for specific services the company provides. However, this often requires much more dedicated efforts and costs a lot. Small startups may have less ability to conduct researches on a large scale over an extended period of time for any significant effects to be observed. - Quantization and Inference Optimization
When it comes to in-house models serving with cloud GPU/in-house GPU servers, the right choice of model quantization, model architecture design and inference engine are of paramount importance. The ability to choose the most cost-effective options will save the company millions and even win more customers (via the latency reduction) over time.
Model Configuration Optimization
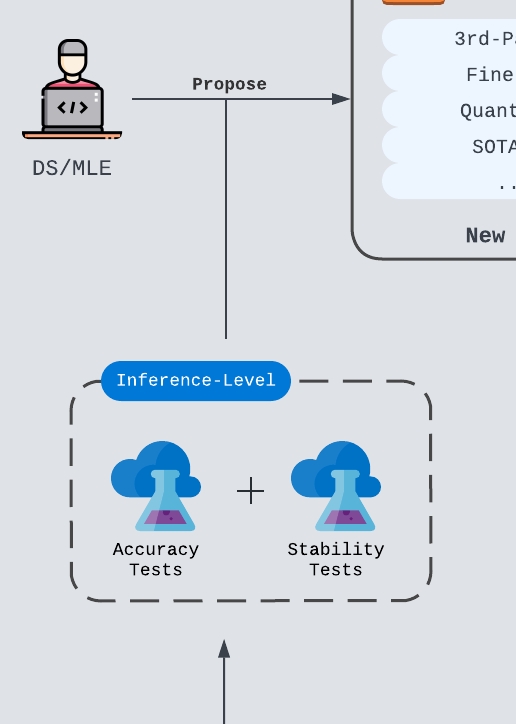
Once ML/DS identified a new candidate model setup, they should immediately explore the right configurations for the setup, such as model temperature, maximum tokens and any pre/post-processing logic required. During the optimization process, two major tests are ran on some golden/sliver production-level datasets (golden: human-labeled, silver: AI-generated):
- Accuracy Tests
The results generated from new model setup are evaluated against ground truth or baseline models (often the champion model in production). A configuration passes the tests only if it produces statistically significant improvement through A/B testing or some internal evaluation criteria. Some prompt engineering is required in this step during tests, but in my opinion, we should setup an automated prompt optimization step after all tests pass to further escalate the performance of the model. Based on past experiences, many attempts actually fail at stability tests or latency tests even with the optimized prompts. - Stability Tests
Stable results are often required in products and tasks like chatbot, classification model and data analysis. This is, however, a frequently ignored aspect for personal projects. Developers tend to encourage variations by not setting temperatures to a high value like0.8or1. There can be pros and cons in this side of story, but we will leave the discussion in the in-depth blogs.
Moder Serving Tests
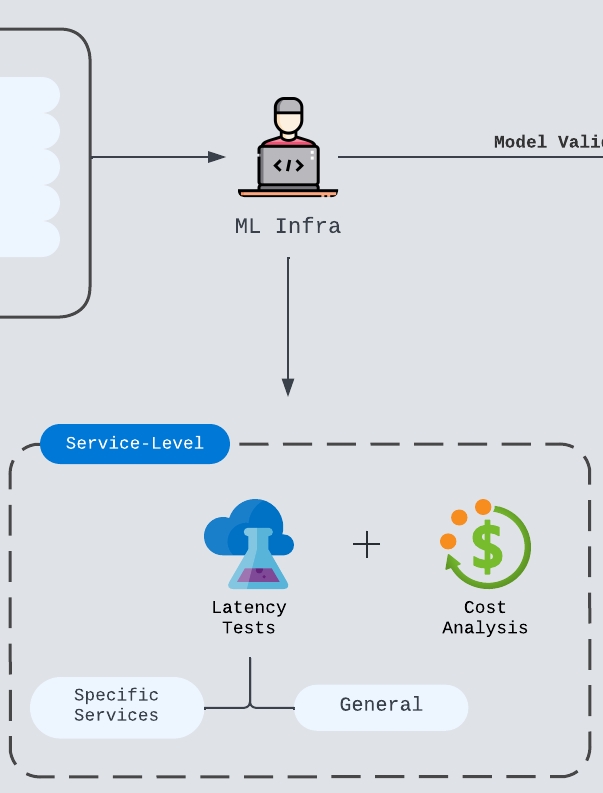
Latency tests will start once the team finalize on the model configurations. This is the phase where ML Infra engineers will run load tests on various use cases and with varying input/output size. Usually it will be a systematic process and easily extensible.
After the latency tests, the team should also consider the economic impact the model update will create. Usually it comes in the form of switching to cheaper vendor, reduced token usage, more efficient development cycle or model deals won due to better features.
Prompt Optimization
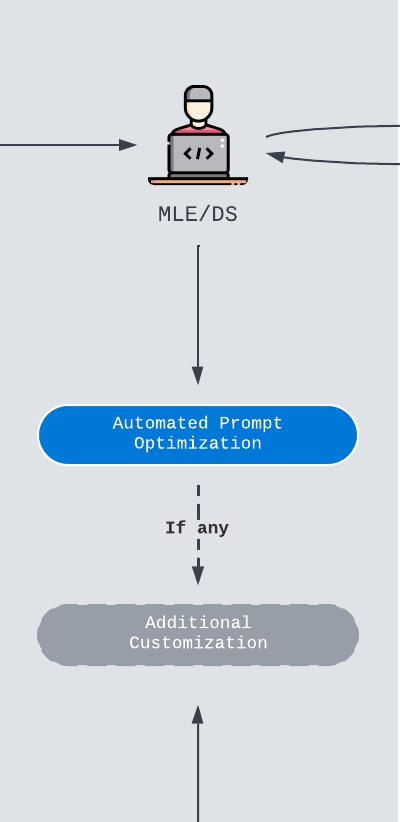
As a final step before staging, we try to further improve the prompts for the specific tasks the proposed model will work on. There are many ways this process can take place. We can setup a model-based optimizer, or improve the prompt via some UI-based prompt iteration strategy, or even come up with customized prompts with right in-context learning methods. We will go through this part with code afterwards.
Staging
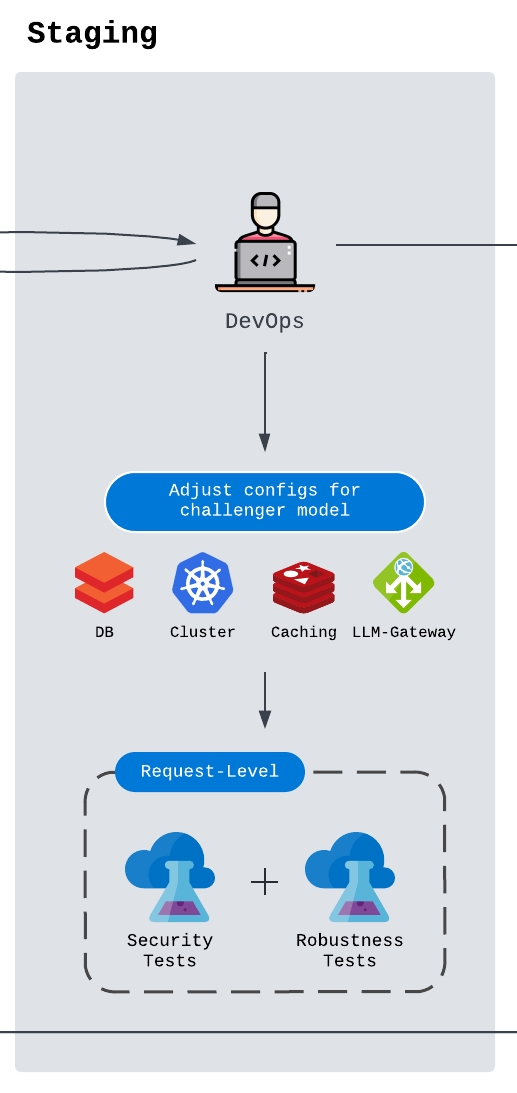
When it comes to UAT environment, the DevOps or ML Infra engineers need to get the full model setup ready, and update these info in the right DB/Cluster/LLM-gateway. Some additional configuration may also be needed for middlewares like streaming tools (e.g. Kafka) or caching (e.g Redis). Once the model is ready to be deployed on UAT environment, the engineers need to conduct end-to-end tests to ensure no security issues are found. This often happens at the request level, where guardrails take place at various checkpoints. Red teaming becomes important at this stage, and engineers may need to work with customer service engineers or product managers to detect additional model-specific loopholes. Any additional potential model/prompt/data drifts can also be identified during the tests to ensure model robustness. Therefore, data curation and engineering can play a critical role at this point. This will be a potential topic I'll share my experience on in the future as well.
Production
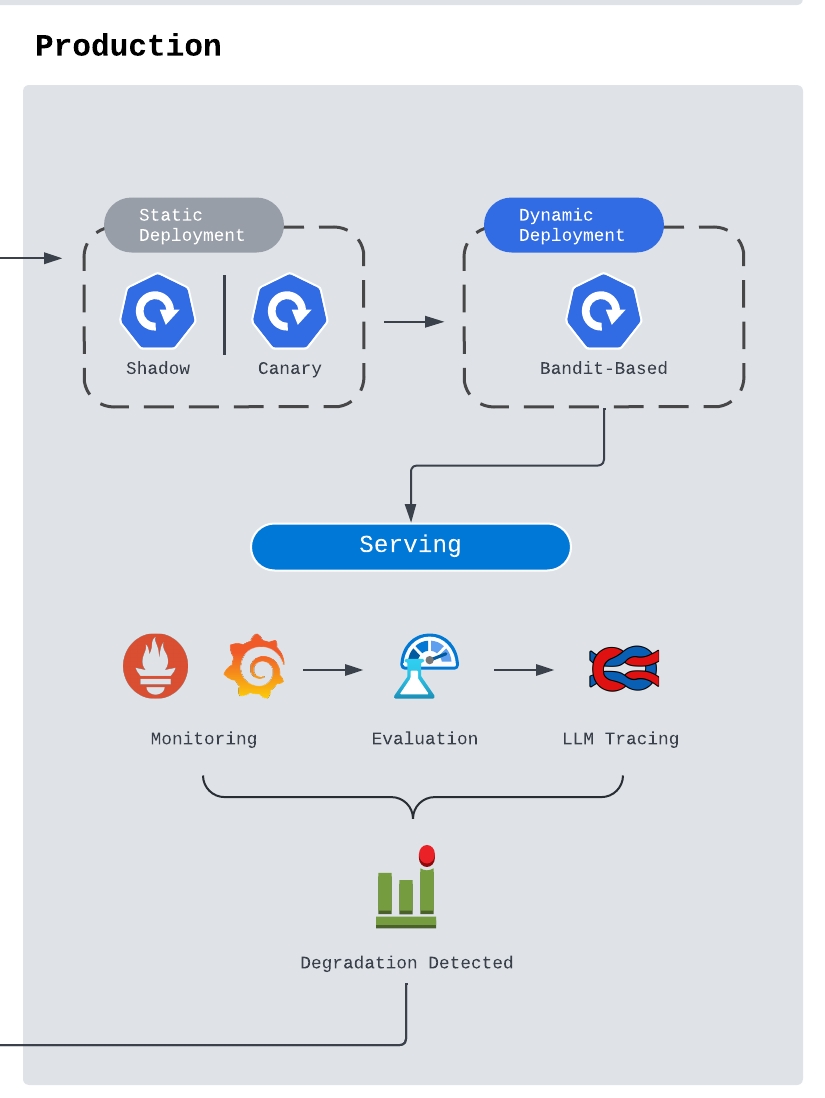
After the UAT tests are done and the model passes screening in staging environment, the code and the model are ready to be deployed. When it comes to deployment, there are two different strategies: static and dynamic. You can refer to my other post on ML deployment for more details. Otherwise, I would suggest starting with static deployment like canary deployment to iteratively route the requests to services utilizing the new model and observe its performance before full deployment. In the meantime, a complete stack of LLM performance monitoring + tracing + alert system should be setup. I I cannot stress more the importance of this part, and will definitely give a full guideline to this section in the future. One major point to mention here is that, once we have detected potential errors that cause any performance degradations, we need to carefully store these errors and augment them if possible. They will be used as valuable data points with negative labels for future finetuning and QA testing. The identified degradation will trigger model fallback or quickly roll back to MLE/DS for further prompt enhancement or configuratio adjustment.
## **To be Continued...**
That wrappes up the first and the most important section of model iterations. Once we delve into details together with some coding exercises, we will find out how intricate the process can become, and there will be several major tradeoff you must make along the way. But before that, let's take a break, digest the content above well, and continue to build great products with great features.
Model Iteration Series: Intro
https://criss-wang.github.io/post/software/model-iteration-intro/