Regression Models: Linear Regression and Regularization
Definition
- It is used for predicting the continuous dependent variable with the help of independent variables.
- The goal is to find the best fit line that can accurately predict the output for the continuous dependent variable.
- The model is usually fit by minimizing the sum of squared errors (OLS (Ordinary Least Square) estimator for regression parameters)
- Major algorithm is gradient descent: the key is to adjust the learning rate
- Explanation in layman terms:
- provides you with a straight line that lets you infer the dependent variables
- estimate the trend of a continuous data by a straight line. using input data to predict the outcome in the best possible way given the past data and its corresponding past outcomes
Various Regulations
Regularization is a simple techniques to reduce model complexity and prevent over-fitting which may result from simple linear regression.
- Convergence conditions differ
- note that regularization only apply on variables (hence
is not regularized!) - L2 norm: Euclidean distance from the origin
- L1 norm: Manhattan distance from the origin
- Elastic Net: Mixing L1 and L2 norms
- Ridge regression:
where is cofficient; more widely used as compared to Ridge when number of variables increases - Lasso regression:
; better when the data contains suspicious collinear variables
Comparison with Logistic Regression
- Linear Regression: the outcomes are continuous (infinite possible values); error minimization technique is ordinary least square.
- Logistic Regression: outcomes usually have limited number of possible values; error minimization technique is maximal likelihood.
Implementations
Basic operations using sklearn packages
1 | from sklearn.linear_model import LinearRegression |
Common Questions
- Is Linear regression sensitive to outliers? Yes!
- Is a relationship between residuals and predicted values in the model ideal? No, residuals should be due to randomness, hence no relationship is an ideal property for th model
- What is the range of learning rate? 0 to 1
Advanced: Analytical solutions
Here let's discuss some more math-intensive stuff. Those who are not interested can ignore this part (though it gives a very important guide on regression models)
1. A detour into Hypothesis representation
We will use
The goal of supervised learning is to learn a hypothesis function
where
For Multiple Linear regression more than one independent variable exit then we will use
where
2. Matrix Formulation
In general we can write above vector as
Now we combine all aviable individual vector into single input matrix of size
We represent parameter of function and dependent variable in vactor form as
So we represent hypothesis function in vectorize form
3. Cost function
A cost function measures how much error in the model is in terms of ability to estimate the relationship between
We can measure the accuracy of our hypothesis function by using a cost function. This takes an average difference of observed dependent variable in the given the dataset and those predicted by the hypothesis function.
To implement the linear regression, take training example add an extra column that is
Each of the m input samples is similarly a column vector with n+1 rows
Let's look at the matrix multiplication concept,the multiplication of two matrix happens only if number of column of firt matrix is equal to number of row of second matrix. Here input matrix
4. Normal Equation
The normal equation is an analytical solution to the linear regression problem with a ordinary least square cost function. To minimize our cost function, take partial derivative of
where
Now we will apply partial derivative of our cost function,
I will throw
Here
Partial derivative
this
Advanced: Model Evaluation and Model Validation
1. Model evaluation
We will predict value for target variable by using our model parameter for test data set. Then compare the predicted value with actual valu in test set. We compute Mean Square Error using formula
where
Here
Below is a sample code for evaluation
1 | # Normal equation |
The model returns
2. Model Validation
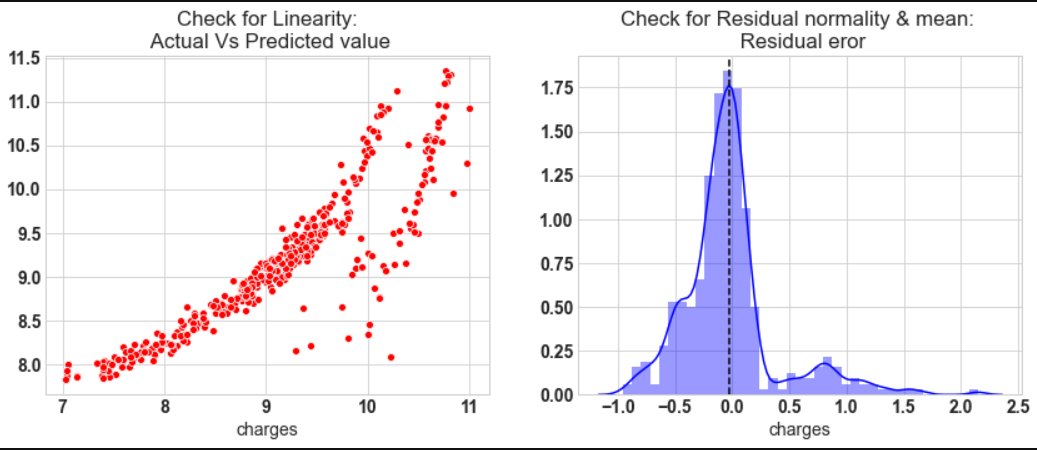
In order to validated model we need to check few assumption of linear regression model. The common assumption for Linear Regression model are following
- Linear Relationship: In linear regression the relationship between the dependent and independent variable to be linear. This can be checked by scatter ploting Actual value Vs Predicted value
- The residual error plot should be normally distributed.
- The mean of residual error should be 0 or close to 0 as much as possible
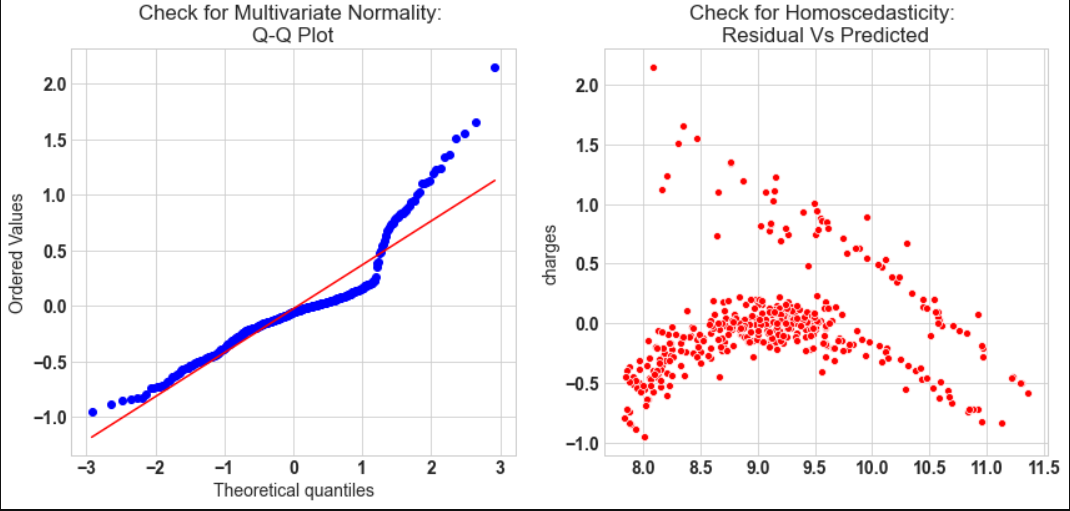
- The linear regression require all variables to be multivariate normal. This assumption can best checked with Q-Q plot.
- Linear regession assumes that there is little or no *Multicollinearity in the data. Multicollinearity occurs when the independent variables are too highly correlated with each other. The variance inflation factor VIF identifies correlation between independent variables and strength of that correlation.
, If VIF >1 & VIF <5 moderate correlation, VIF < 5 critical level of multicollinearity. - Homoscedasticity: The data are homoscedastic meaning the residuals are equal across the regression line. We can look at residual Vs fitted value scatter plot. If heteroscedastic plot would exhibit a funnel shape pattern.
The model assumption linear regression as follows
- In our model the actual vs predicted plot is curve so linear assumption fails
- The residual mean is zero and residual error plot right skewed
- Q-Q plot shows as value log value greater than 1.5 trends to increase
- The plot is exhibit heteroscedastic, error will insease after certian point.
- Variance inflation factor value is less than 5, so no multicollearity.
Regression Models: Linear Regression and Regularization
https://criss-wang.github.io/post/blogs/supervised/regressions-1/