Ensemble Models: Overview
Overview
An important techinque in machine learning is ensemble models. It includes some very popular techniques like bootstraping and boosting. In the upcoming blogs, I will outline these models in detail, and give comparisons when necessary. The mathematical proofs are omitted for simplicity. However, I highly recommend interested readers to take a look at the theoretical foundations of these models to gain great intuitions about the ideas behind ensemble models.
Intro
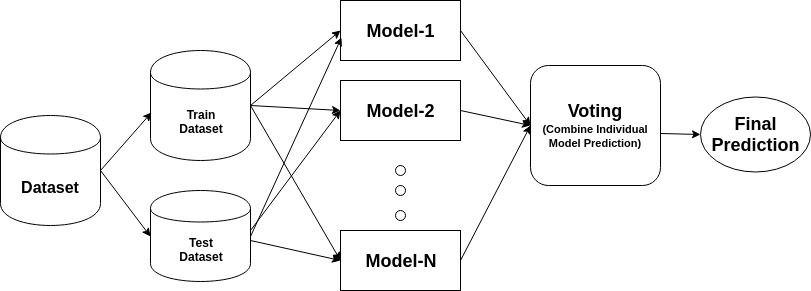
- An ensemble model is a composite model which combines a series of low performing or weak classifiers with the aim of creating a strong classifier.
- Here, individual classifiers vote and final prediction label returned that performs majority voting.
- Now, these individual classifiers are combined according to some specific criterion to create an ensemble model.
- These ensemble models offer greater accuracy than individual or base classifiers.
- These models can parallelize by allocating each base learner to different mechanisms.
- So, we can say that ensemble learning methods are meta-algorithms that combine several machine learning algorithms into a single predictive model to increase performance.
- Ensemble models are created according to some specific criterion as stated below:
- Bagging - They can be created to decrease model variance using bagging approach.
- Boosting - They can be created to decrease model bias using a boosting approach.
- Stacking - They can be created to improve model predictions using stacking approach.
- It can be depicted with the help of following diagram.
1. Bagging
- Bagging stands for bootstrap aggregation.
- It combines multiple learners in a way to reduce the variance of estimates.
- For example, random forest trains N Decision Trees where we will train N different trees on different random subsets of the data and perform voting for final prediction.
- Bagging ensembles methods are Random Forest and Extra Trees.
2. Boosting
- Boosting algorithms are a set of the weak classifiers to create a strong classifier.
- Strong classifiers offer error rate close to 0.
- Boosting algorithm can track the model who failed the accurate prediction.
- Boosting algorithms are less affected by the overfitting problem.
- The following three algorithms have gained massive popularity in data science competitions
- AdaBoost (Adaptive Boosting)
- Gradient Tree Boosting (GBM)
- XGBoost
- We will discuss AdaBoost in this kernel and GBM and XGBoost in future posts.
3. Stacking
Stacking (or stacked generalization) is an ensemble learning technique that combines multiple base classification models predictions into a new data set.
This new data are treated as the input data for another classifier.
This classifier employed to solve this problem. Stacking is often referred to as blending.
Blending (average) ensemble model: Fits the base learners to the training data and then, at test time, average the predictions generated by all the base learners.
- Use
VotingClassifierfromsklearnthat:- fit all the base learners on the training data
- at test time, use all base learners to predict test data and then take the average of all predictions.
- Use
Stacked ensemble model: Fits the base learners to the training data. Next, use those trained base learners to generate predictions (meta-features) used by the meta-learner (assuming we have only one layer of base learners). There are few different ways of training stacked ensemble model:
- Fitting the base learners to all training data and then generate predictions using the same training data it was used to fit those learners. This method is more prune to overfitting because the meta learner will give more weights to the base learner who memorized the training data better, i.e. meta-learner won't generate well and would overfit.
- Split the training data into 2 to 3 different parts that will be used for training, validation, and generate predictions. It's a suboptimal method because held out sets usually have higher variance and different splits give different results as well as learning algorithms would have fewer data to train.
- Use k-folds cross validation where we split the data into k-folds. We fit the base learners to the (k - 1) folds and use the fitted models to generate predictions of the held out fold. We repeat the process until we generate the predictions for all the k-folds. When done, refit the base learners to the full training data. This method is more reliable and will give models that memorize the data less weight. Therefore, it generalizes better on future data.
4. How are base-learners classified
- Base-learners are classified into two types.
- On the basis of the arrangement of base learners, ensemble methods can be divided into two groups.
- Parallel ensemble: base learners are generated in parallel for example - Random Forest.
- Sequential ensemble: base learners are generated sequentially for example AdaBoost.
- On the basis of the type of base learners, ensemble methods can be divided into two groups.
- Homogenous ensemble: uses the same type of base learner in each iteration.
- Heterogeneous ensemble: uses the different type of base learner in each iteration.
Bagging vs Boosting
1. Selecting the best technique- Bagging or Boosting
- Depends on the data, the simulation and the circumstances.
- Bagging and Boosting decrease the variance of your single estimate as they combine several estimates from different models. So the result may be a model with higher stability.
- If the problem is that the single model gets a very low performance, Bagging will rarely get a better bias. However, Boosting could generate a combined model with lower errors as it optimises the advantages and reduces pitfalls of the single model.
- By contrast, if the difficulty of the single model is over-fitting, then Bagging is the best option. Boosting for its part doesn’t help to avoid over-fitting.
- In fact, this technique is faced with this problem itself. For this reason, Bagging is effective more often than Boosting.
2. Similarities between Bagging and Boosting
- Both are ensemble methods to get N learners from 1 learner.
- Both generate several training data sets by random sampling.
- Both make the final decision by averaging the N learners (or taking the majority of them i.e Majority Voting).
- Both are good at reducing variance and provide higher stability.
3. Differences between Bagging and Boosting
- Bagging is the simplest way of combining predictions that belong to the same type while Boosting is a way of combining predictions that belong to the different types.
- Bagging aims to decrease variance, not bias while Boosting aims to decrease bias, not variance.
- In Baggiing each model receives equal weight whereas in Boosting models are weighted according to their performance.
- In Bagging each model is built independently whereas in Boosting new models are influenced by performance of previously built models.
- In Bagging different training data subsets are randomly drawn with replacement from the entire training dataset. In Boosting every new subsets contains the elements that were misclassified by previous models.
- Bagging tries to solve over-fitting problem while Boosting tries to reduce bias.
- If the classifier is unstable (high variance), then we should apply Bagging. If the classifier is stable and simple (high bias) then we should apply Boosting.
- Bagging is extended to Random forest model while Boosting is extended to Gradient boosting.
Ensemble Models: Overview
https://criss-wang.github.io/post/blogs/supervised/ensemble-0/