Recommender Systems: I. Content-Based Filtering And Collaborative Filtering
Overview
The rapid growth of data collection has led to a new era of information. Data is being used to create more efficient systems and this is where Recommendation Systems come into play. Recommendation Systems are a type of information filtering systems as they improve the quality of search results and provides items that are more relevant to the search item or are realted to the search history of the user. They are used to predict the rating or preference that a user would give to an item. Almost every major tech company has applied them in some form or the other: Amazon uses it to suggest products to customers, YouTube uses it to decide which video to play next on autoplay, and Facebook uses it to recommend pages to like and people to follow. Moreover, companies like Netflix and Spotify depend highly on the effectiveness of their recommendation engines for their business and success.
Traditional recommender system models
There are basically three types of traditional recommender systems, let's use the example of movie recommendation (e.g. Netflix):
- Demographic Filtering: They offer generalized recommendations to every user, based on movie popularity and/or genre. The System recommends the same movies to users with similar demographic features. Since each user is different , this approach is considered to be too simple. The basic idea behind this system is that movies that are more popular and critically acclaimed will have a higher probability of being liked by the average audience.
- Content Based Filtering: They suggest similar items based on a particular item. This system uses item metadata, such as genre, director, description, actors, etc. for movies, to make these recommendations. The general idea behind these recommender systems is that if a person liked a particular item, he or she will also like an item that is similar to it.
- Collaborative Filtering: This system matches persons with similar interests and provides recommendations based on this matching. Collaborative filters do not require item metadata like its content-based counterparts.
In later blogs, we will talk about more recent models for recommender systems, including factorization machines and deep learning based models.
Content Based Filtering
1. Definition
- Use additional information about users and/or items.
- Example: User features: age, the sex, the job or any other personal information
- Exmaple: Item features: the category, the main actors, the duration or other characteristics for the movies.
- Main idea: given the set of features (both User and Item), apply a method to identify the model that explain the observed user-item interactions.
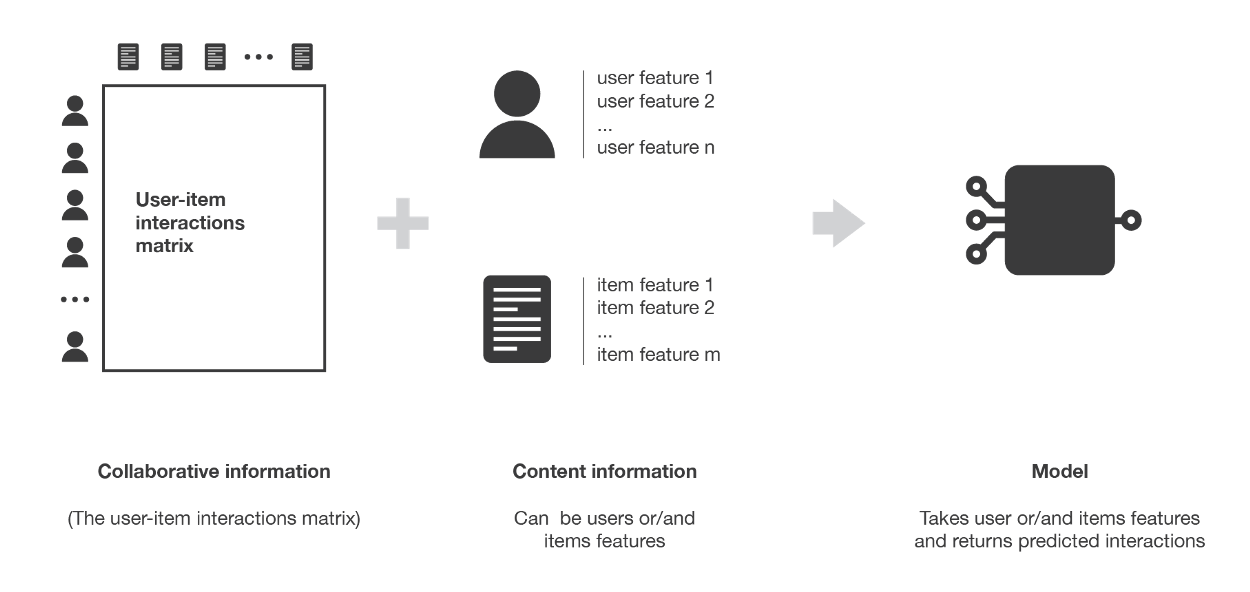
Content Flow - Little concern about "Cold Start": new users or items can be described by their characteristics (content) and so relevant suggestions can be done for these new entities
- One key tool used:
Term Frequency-Inverse Document Frequency (TF-IDF):- TF: the frequency of a word in a document
- IDF: the inverse of the document frequency among the whole corpus of documents.
- log: log function is taken to dampen the effect of high frequency word (0 vs 100
0 vs 2 (log100))
- Note that normalization is needed before we apply
TF-IDFbecause the initial feature map are all 1's and 0's, but the log function will remove all these differentiation. In the end the TF score will just be 1/0
2. Limitation
- They are not good at capturing inter-dependence or complex behaviours. For example: A user may prefer gaming + tv the most while a pure tv is not really his favourate.
3. Code Sample
1 | import numpy as np # linear algebra |
Collaborative Filtering
1. Definition
- Based solely on the past interactions recorded between users and items in order to produce new recommendations
- Main idea: Past user-item interactions are sufficient to detect similar users and/or similar items and make predictions based on these estimated proximities.
- Every user and item is described by a feature vector or embedding. It creates embedding for both users and items on its own. It embeds both users and items in the same embedding space.
- 2 Major Types:
- Memory Based
- Users and items are represented directly by their past interactions (large sparce vector)
- Recommendations are done following nearest neighbour information
- No latent model is assumed
- Theoretically a low bias but a high variance.
- Usualy recommend those items with high rating for a user
: : the rating given to by user : users similar to / items similar to : respective ratings : similarity score for -th item/user similar to / (deduced using the similarity metircs shown below)
- Similarity Metrics:
Cosine SimilarityDot ProductEuclidean distancePearson Similarity:
- Limitations:
- Don't scale easily
- KNN algorithm has a complexity of O(ndk)
- Users may easily fall into a "information confinement area" which only give too precise/general information
- Overcome Limitation: Use Approximate nearest neighbour (ANN) or take advantage of sparse matrix
- 2 Types:
- User-User:
- Identify users with the most similar "interactions profile" (nearest neighbours) in order to suggest items that are the most popular among these neighbours (and that are "new" to our user).
- We consider that two users are similar if they have interacted with a lot of common items in the same way (similar rating, similar time hovering…).
Prevents overfitting - As, in general, every user have only interacted with a few items, it makes the method pretty sensitive to any recorded interactions (high variance)
- Only based on interactions recorded for users similar to our user of interest, we obtain more personalized results (low bias)
- Item-Item:
- Find items similar to the ones the user already "positively" interacted with
- Two items are considered to be similar if most of the users that have interacted with both of them did it in a similar way.
- A lot of users have interacted with an item, the neighbourhood search is far less sensitive to single interactions (lower variance)
- Interactions coming from every kind of users are then considered in the recommendation, making the method less personalised (more biased)
- VS User-User: Less personalized, but more robust
- User-User:
- Model Based
- New reprensentations of users and items are build based on a model (small dense vectors)
- The model "derives" the relevant features of the user-item interactions
- Recommendations are done following the model information
- May contain interpretability issue
- Theoretically a higher bias but a lower variance
- 3 Types:
- Clustering
- Simple KNN/ANN will do on these metrices
- Matrix Factorization
- Main assumption: There exists a very low dimensional latent space of features in which we can represent both users and items and such that the interaction between a user and an item can be obtained by computing the dot product of corresponding dense vectors in that space.
- Generate the factor matrices as feature matrices for users and items.
- Idea:
: Interaction matrix of ratings, usually sparse : User matrix : Item matrix : the dimension of the latent space
- Advanced Factorization methods:
- SVD:
- Not so well due to the sparsity of matrix
: is item matrix; is user matrix
- WMF (Weighted Matrix Factorization)
- Weight applied to rated/non-rated entries
- Similar to NMF but also consider non-rated ones by associating a weight to each entry
- NMF:
- Uses only the observed or rated one
- Performs well with sparse matrices
where indicates the -th item rated by -th user
- SVD:
- Minimizing the objective function
- Most common:
Weighted Alternating Least Squares - Formula:
- Regularized minimization of “rating reconstruction error”
- Optimization process via Gradient Descent (Reduce runtime by batch running)
- Instead of solving for
and together, we alternate between the above two equations. - Fixing
and solving for - Fixing
and solving for
- Fixing
- This algorithm gives us an approximated result (two equations are not convex at the same time
can't reach a global minimum local minimum close to the global minimum)
- Most common:
- Clustering
- Memory Based
- For a fixed set of users and items, new interactions recorded over time bring new information and make the system more and more effective.
- Solution to "Cold Start" problem:
- Heuristics to generate embeddings for fresh items
- Recommending random items to new users/recommend new item to random users
- Recommending popular items to new usres/recommend new items to most active users
- Recomeending a set of various items to new users or a new item to a set of various users
- Use a non collaborative method for early life of the user/item
- Projection in WALS (given current optimal
and )
- Heuristics to generate embeddings for fresh items
2. Pros & Cons
Pros
- Require no information about users or items (more versatile)
Cons
- Cold Start problem:
- Impossible to recommend anything to new users or to recommend a new item to any users
- Many users or items have too few interactions to be efficiently handled.
3. Comparison with Content Based Method
- Content based methods suffer far less from the cold start problem than collaborative approaches
- CB is much more constrained (because representation of users and/or items are given)
- CB tends to have the highest bias but the lowest variance
4. Code samples
1 | # Import libraries |
Recommender Systems: I. Content-Based Filtering And Collaborative Filtering
https://criss-wang.github.io/post/blogs/recom_sys/recommender-1/