Variational Inference
Introduction
1. Background of Bayesian methods
In the field of machine learning, most would agree that frequentist approaches played a critical role in the development of early classical models. Nevertheless, we are witnessing the increasing significance of Bayesian methods in modern study of machine learning and data modelling. The simple-looking Bayes' rule
2. Problem with Bayesian methods: intractable integral
While the rule looks easily understandable, the numerical computation is hard in reality. One major issue is the intractable integral
3. Main idea of variational inference
In variational inference, we can avoid computing the intractable integral by magically modelling the posterior
Understanding Variational Bayesian method
In this section, we demonstrate the theory behind variational Bayesian methods.
1. Kullback-Leibler Divergence
As mentioned above, variational inference needs a distribution
KL divergence is defined as
Where
if
is low, the divergence is generally low. if
is high and is high, the divergence is low. if
is high and is low, the divergence is high, hence the approximation is not ideal.
Take note of the following about use of KL divergence in Variational Bayes:
KL divergence is not symmetric, it's easy to see from the formula that
as the approximation distribution is usually different from the target distribution . In general, we focus on approximating some regions of
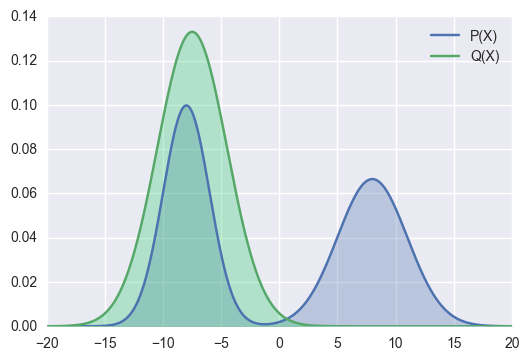
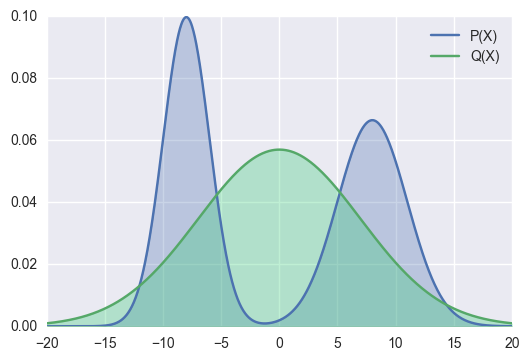
as good as possible (Figure 1 (a)). It is not necessary for the to nicely approximate every part of As a result (usually called forward divergence) is not ideal. Because for some regions which we don't want to care, if , the KL divergence will be very large, forcing to take a different form even if it fits well with other regions of (refer to Figure 1(b)). On the other hand, (usually called reverse KL divergence) has the nice property that only regions where requires and to be similar. Consequently, reverse KL divergence is more commonly used in Variational Inference.
2. Evidence lower bound
Usually we don't directly minimizing KL divergence to obtain a good approximated distribution. This is because computing
The approximation using reverse KL divergence usually gives good empirical results, even though some regions of
We can directly conclude by the fact
- By the definition of marginal probability, we have
, take log on both side we have:
- The last 2 lines follow from Jensen's Inequality which states that for a convex function
, we have
This term
General procedure
In general, a variational inference starts with a family of variational distribution (such as the mean-field family described below) as the candidate for
Mean Field Variational Family
1. The "Mean Field" Assumptions
As shown above, the particular variational distribution family we use to approximate the posterior
where
2. Derivation of optimal
Now in order to derive the the optimal form of distribution for
With this new expression, we can consider maximizing
We take the derivative with respect to
where
The funtional derivative of this expression actually requires some knowledge about calculus of variations, specifically Euler-Lagrange equation.
3. Variable update with Coordinate Ascent
From equation
Compute values (if any) that can be directly obtained from data and constants
Initialize a particular
to an arbitrary value Update each variable with the step function
Repeat step 3 until the convergence of ELBO
A more detailed example of coordinate ascent will be shown in next section with the univariate gaussian distribution example. A point to take note that in general, we cannot guarantee the convexity of ELBO function. Hence, the convergence is usually to a local maximum.
Example with Univariate Gaussian
We demonstrate the mean-field variational inference with a simple case of observations from univariate Gaussian model. We first assume there are
Here
where
Note that sometimes some latent variable has higher priority that others. The choice of this variable depends on the exact question in hand.
1. Compute independent
Next, we apply approximation via
- Compute the expression for
:
Note that here
- Compute the expression for
A closer look at the result
2. Variable update until ELBO convergence}
Now that we have
Using the updated
Compute
and as they can be derived directly from the data and constants based on their formula Initialize
to some random value Update
with current values of and Update
with current values of and Compute ELBO value with the variables
& updated with the parameters in step 1 - 4 Repeat the last 3 steps until ELBO value doesn't vary by much
As a result of the algorithm, we obtain an approximation
Extension and Further result
In this section, we briefly outline some more theory and reflection about general variational Bayesian methods. Due to space limitations, we only provide a short discussion on each of these.
Exponential family distributions in Varational Inference
A nice property of the exponential family distribution is the presence of conjugate priors in closed forms. This allows for less computationally intensive approaches when approximating posterior distributions (due to reasons like simpler optimization algorithm applicable and better analytical forms). Further more, Gharamani & Beal even suggested in 2000 that if all the
A great achievement in the field of variational inference is the generalized update formula for Exponentialfamily-conditional models. These models has conditional densities that are in exponential family. The nice property of exponential family leads to an amazing result that the optimal approximation form for posteriors are in the same exponential family as the conditional. This has benefits a lot of well-known models like Markov random field and Factorial Hidden Markov Model.
Comparison to other Inference methods
The ultimate results of variational inference are the approximation for the entire posterior distribution about the parameters and variables in the target problem with some observations instead of just a single point estimate. This serves the purpose of further statistical study of these latent variables, even if their true distributions are analytically intractable. Another group of inference methods commonly used to achieve the similar aim is Markov chain Monte Carlo (MCMC) methods like Gibbs sampling, which seeks to produce reliable resampling of given observations that help to approximate latent variables well. Another common Bayesian method that has a similar iterative variable update procedure is Expectation Maximization (EM). For EM, however, only point estimates of posterior distribution are obtained. The estimates are "Expectation maximizing" points, which means any information about the distribution around these points (or the parameters they estimate) are not preserved. On the other hand, despite the advantage of "entire distribution" Variational inference has, its point estimates are often derived just by the mean value of the approximated distributions. Such point estimates are often less significant compared to those derived using EM, as the optimum is not directly achieved from the Bayesian network itself, but the optimal distributions inferred from the network.
Popular algorithms applying variational inference
The popularity of variational inference has grown to even surpass the classical MCMC methods in recent years. It is particularly successful in generative modeling as a replacement for Gibbs sampling. The methods often show better empirical result than Gibbs sampling, and are thus more well-adopted. We here showcase some popular machine learning models and even deep learning models that heavily rely on variational inference methods and achieved great success:
Latent Dirichlet Allocation: With the underlying Dirichlet distribution, the model applies both variational method (for latent variable distribution) and EM algorithm to obtain an optimal topic separation and categorization.
variational autoencoder: The latent Gaussian space (a representation for the input with all the latent variables and parameters) is derived from observations, and fine-tuned to generate some convincing counterparts (a copy for instance) of the input.
These models often rely on a mixture of statistical learning theories, but variational inference is definitely one of the key function within them.
Variational Inference
https://criss-wang.github.io/post/blogs/prob_and_stats/variational-inference/