An overview of Hidden markov model and its algorithms
Overview
Stochastic Process is a critical piece of knowledge in statistical learning. It's also an important piece in the increasing popular reinforcement learning field. I feel like I might apply its algorithms or do research work on it in the future. Hence, I create this blog to introduce an important concept, hidden markov model (HMM), and some useful algorithms and their intuitions for HMM.
Markov Chain
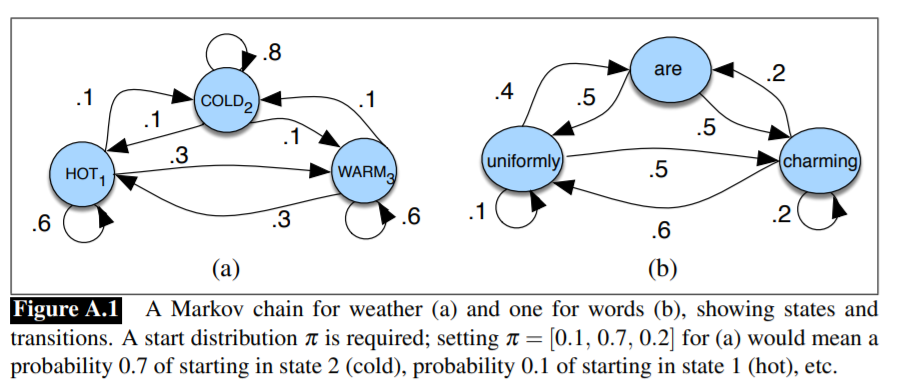
The HMM is based on augmenting the Markov Chain(MC), which is a type of a random process about a set of states. The transition from one state to another depends on certain probabilities
[1]:https://web.stanford.edu/~jurafsky/slp3/A.pdf
HMM Definition
A Markov chain is useful when we need to compute a probability for a sequence of observable events. In many cases, however, the events we are interested in are hidden: we don’t observe them directly. For example we don't normally observe part-of-speech tags in a text. Rather, we see words, and must infer the tags from the word sequence. We call the tags hidden because they are not observed. A hidden Markov model (HMM) allows us to talk about both observed events (like words that we see in the input) and hidden events (like part-of-speech tags) that we think of as causal factors in our probabilistic model. In HMM, we use observations
- Problem 1 (Likelihood): Given an HMM with transition probabilities
and observation probabilities and an observation sequence , determine the likelihood . - Problem 2 (Decoding): Given an observation sequence
and an HMM , discover the best hidden state sequence . - Problem 3 (Learning): Given an observation sequence
and the set of states in the HMM, learn the HMM parameters and .
Algorithms
1. The Forward Algorithm - Likelihood solver
The forward algorithm is a dynamic programming method that computes the observation probability by summing over the probabilities of all possible hidden state paths that could generate the observation sequence, but it does so efficiently by implicitly folding each of these paths into a single forward trellis, which computes the probability of being in state
From above, we can quickly derive the result by:
- first initialize
. - Recrusively apply the above expression (1) for
. - Compute
2. The Viterbi Algorithm - Decoding solver
Like forwarding algorithm, Viterbi is also DP that makes uses of a dynamic programming Viterbi trellis. The idea is to process the observation sequence left to right, filling out the trellis. Each cell of the trellis,
Here, a major difference from (1) is that we now take the most probable of the extensions of the paths that lead to the current cell. In addition to the max value
This is called backpointers. We need this value because while the forward algorithm needs to produce an observation likelihood, the Viterbi algorithm must produce a probability and also the most likely state sequence. We compute this best state sequence by keeping track of the path of hidden states that led to each state, and Viterbi backtrace then at the end backtracing the best path to the beginning (the Viterbi backtrace).
Finally, we can compute the optimal score and path
We use a demo code to illustrate the process. The code for forwarding algorithm and Forward-Backward Algorithm can be implmented in a similar fashion.
1 | import numpy as np |
3. Forward-backward algorithm - Learning solver
The standard algorithm for HMM training is the forward-backward, or Baum-Welch Welch algorithm, a special case of the Expectation-Maximization (EM) algorithm. The algorithm will let us train both the transition probabilities
For a real HMM, we only get observations, and cannot compute which observation is from which state directly from an observation sequence since we don't know which path of states was taken through the machine for a given input. What's more, we don't even know when is a hidden state present. The Baum-Welch algorithm solves this by iteratively estimating the number of times a state occurs. We will start with an estimate for the transition and observation probabilities and then use these estimated probabilities to derive better and better probabilities. And we're going to do this by computing the forward probability for an observation and then dividing that probability mass among all the different paths that contributed to this forward probability.
First, we define backward probability
We can actually think of it as a reverse of the forwarding probability
- First initialize
. - Recrusively apply
. - Compute
Now, we start the actual work. To estimate the
How do we compute the expected number of transitions from state
since we can easily compute
we get
Similarly, by considering expected number of times in state
We are ready to compute
Using (3), (4), we can apply EM algorithm easily, as demonstrated below:
- Initialize
- iterate until Convergence:
E-step:
$$\xi_t(i, j) = \frac{\alpha_t(i) \widehat{P}_{ij} \widehat{P^H}j\left(o{t+1}\right) \beta_{t+1}(j)}{\sum_{j=1}^N \alpha_t(j) \beta_t(j)} \; \forall t, i \; \text{and} j
$$M-step:
This concludes the blog, thank you!
An overview of Hidden markov model and its algorithms
https://criss-wang.github.io/post/blogs/prob_and_stats/hidden-markov-models/