Testing in Machine Learning
ML Testing
The complexity of ML models and the iterative nature of their development pose unique challenges in ensuring their reliability, robustness, and performance. In this blog post, we delve into the critical aspect of ML testing in MLOps, exploring various strategies, tools, and best practices to ensure the quality and effectiveness of ML models in production environments.
Data quality and diversity
Data quality and diversity are critical factors in ML testing, ensuring that models perform reliably across different scenarios and datasets. This means the following aspects need to be tested thoroughly:
Data Consistency:
Ensuring data consistency involves validating the integrity, accuracy, and completeness of datasets used for training and testing ML models. Techniques such as data profiling, schema validation, and anomaly detection help identify inconsistencies and errors in the data.As a baseline, we shall always check for:
- Implementation errors (i.e., written logic, error handling) during ETL of data
- Encoding is often something people forget to check. However this is extremely important in the ML domain.
- Input/Ouput Shape and Range misalignment from the model
- Potential Train/Test/Validation Split issue (e.g. class imbalance among the split) and Potential data leakages (e.g. from train set to test set)
- UNEXPECTED Feature correlation and Temporal dependencies within dataset
- Implementation errors (i.e., written logic, error handling) during ETL of data
Data Drift:
Data drift refers to changes in the underlying data distribution over time, leading to performance degradation in ML models. Monitoring data drift involves comparing model predictions with ground truth labels and detecting deviations from expected behavior. Techniques like drift detection and concept drift detection are employed to locate data drift issues.As a baseline, we shall always check for:
- Distribution drift
- Kolmogorov-Smirnov Test for numerical CDF drift testing
- Chi-square Test for categorical drift testing
- Performance drift caused by domain shifts or concept shifts. Typically conducted during production stage and can be in the form of supervised/unsupervised/semi-supervised
- Distribution drift
Model quality
Model quality encompasses various aspects such as regression, robustness, and domain adaptation, ensuring that ML models generalize well and exhibit reliable performance across diverse datasets.
Metrics definition & evaluation framework
Before stepping into regression testing or robustness testing, you MUST ensure the correct implementation of your evaluation framework. It will a huge waste of time if you spend tons of time trying to improving upon a problematic metric results. Make sure all the custom implementation of evaluation pipeline and metrics are thoroughly tested.Regression testing
Regression testing involves validating model outputs against expected outcomes to detect regression bugs and ensure model correctness. Regression can happen during training time and inference time, so it is critical to provide robust UAT testing and Prod testing, and set up alarms carefully. This is a major task in many of the industry-level ML projects, as it significantly affects the product’s quality.As a baseline, we shall always check for :
- [Training] Convergence
- [Training] Overfitting / Underfitting
- [Training + Inference] Directional expectation (e.g. snow shouldn’t be expected under high temperature)
- [Inference] Server testing (batch/streaming features)
Robustness
Model robustness refers to the ability of ML models to perform consistently in the presence of perturbations, adversarial attacks, and out-of-distribution data.As a baseline we should always consider the following methods:
- adversarial training with input perturbation
- robust optimization over model with surrogate functions / loss that accounts for perturbation
Fairness & Bias
Ensuring fairness and mitigating bias in ML models are essential for ethical AI and preventing discriminatory outcomes. This includes identifying and mitigating biases related to race, gender, age, and other demographic factors. Techniques such as fairness-aware training, bias detection, and algorithmic auditing help address ethical concerns and promote fairness and transparency in ML systems. In post-GPT area, this often means alignment for LLMs. However, many explicit components like Diverse Representation, Transparency and Explainability and Bias Monitoring (preprocessing/data, discriminatory inference, evaluation framework, etc) need to be considered. The focus also differ from business to business. Hence, I would not provide a generic baseline here. Instead, I’d recommend taking a deep dive into the IBM’s AI Fairness 360 (AIF360) for the specific biases you’d like to mitigate and the relevant metrics used. On the other hand, you may also resort to LLM evaluators to complete the task for you (at a risk of evaluation bias).
System Testing
Ensuring robust system is another critical part of the MLOps workflow. The context may diverge based on inference or training pipeline. However, both have the target of maintaining model correctness, scalability and fault tolerance.
From a training-based aspect, we need to consider
- If multi-node or multi-server (or both) setup is secured with failure recovery mechanisms like model checkpointing and replica syncing
- If CPU/GPU bandwidth is fully utilized and memory is fully utilized
- If storage is causing a issue
- If network congestions / latencies can be addressed as desired
From an inference-based aspect, we need to consider
- If model can serve streaming/batch/real-time functionalities
- If model can have low latency, even under heavy traffic, i.e. load testing or stress testing (*note: this may be addressed by devop team, but we should also pay attention to the processing time change due to heated servers)
ML Testing but SWE
To write high quality ML code doesn’t just mean we need to consider all the data science and ML research perspective, but also the basic software engineering principles need to be highly respected. Towards this end, we have to write robust unit tests. However, the guideline may differ from the traditional swe practices. Here we have the following suggestions when performing unit testing in ML:
- Use small, simple data samples: Avoid loading data files as sample data. Use one or two data entries defined directly in the test files if possible.
- When viable, test against random or empty weights to get rid of any assumption about model weights and ensure the architecture’s robustness on any embedding layers
- Write critical tests against the actual model: If they take a while to run, you may choose to mark
@slowon the test and run only when needed (e.g., pre-commit and pre-merge). - Check post-processing logics such as diversification or filtering recommendations to ensure business logic runs correctly after the ML part
ML Testing CI/CD
ML testing, just like SWE testing, is a continuous effort. We can often automate it via CI/CD. However, unlike SWE testing, some of the efforts are destined to give non-deterministic outcomes, and consequently requires human-in-the-loop. Towards this end, CI/CD in ml is a more challenging task, and have less of a standardized way to follow. Nonetheless, there are still guidelines we can follow. I really like how Jeremy Jordan depicts a canonical model development pipeline would look like as follows:
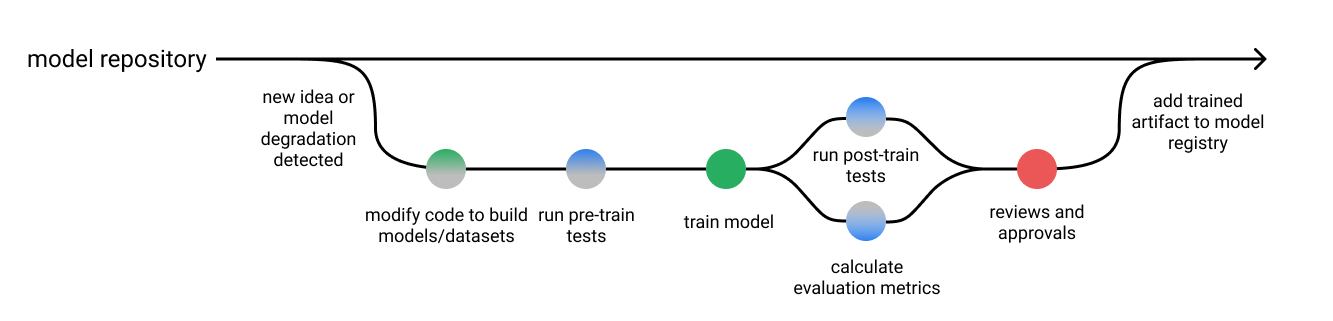
If you are interested in more detailed descriptions, for e.g. how dev/uat/prod testing would differ in a ml-driven project in big companies, I’d recommend this book from Databricks. It contains tons of great lessons on how to build a robust system, which includes testings in CI/CD on ML models.
References
Testing in Machine Learning